方便快捷生成语法树的工具,使得你不用手写 Lexer 和 Parser(毕竟都是机械工作,真的没意思)。
快说,谢谢 ANTLR。
ANTLR
ANTLR (ANother Tool for Language Recognition) 是一款强大的语法分析器生成工具,基于 LL(*) 分析技术。ANTLR 可以通过解析用户自定义的上下文无关文法,自动生成词法分析器、语法分析器。
ANTLR 支持多种代码生成目标,包括 Java、C++、C#、Python、Go、Javascript、Swift等。
语法文件 .g4
ANTLR 源文件的扩展名为 .g4。ANTLR会读入 .g4 文件,并生成对应的词法分析程序和语法分析程序。
在 .g4 文件的开头,需要给文件中定义的语法起个名字,这个名字必须和文件名相同。
1 | // calc.g4 |
ANTLR 中的注释和 C 语言相同,都是用 // 和 /**/ 作为注释符号。
首先定义词法解析规则:ANTLR 约定词法解析规则以大写字母开头。和 bison 类似,ANTLR 使用 : 代表 BNF 文法中的 -> 或者 ::= ;同一终结符 / 非终结符的不同规则使用 | 分割;使用 ;表示一条终结符 / 非终结符的规则的结束。
1 | // calc.g4 |
然后定义语法解析规则:ANTLR 约定语法解析规则以小写字母开头,默认将第一个语法规则左部的非终结符作为语法的起始符号。
1 | // calc.g4 |
前面提到,ANTLR 基于 LL(*) 分析技术,这是一种 自顶向下 的分析方法,而自顶向下的分析方法不能处理具有 左递归 的文法,但在 ANTLR 的实现中有一些改进:如果直接左递归规则中存在一个非左递归的选项,那么它仍然是可以处理的,比如 expr 那一条中的选项 term,但是 ANTLR 仍然不能处理没有非左递归选项的左递归规则以及间接左递归。
ANTLR隐式地允许指定 运算符优先级 ,规则中排在前面的选项优先级比后面的选项优先级更高。所以上面的规则甚至可以改写成这样(当然非常不好就是了):
1 | // calc.g4 |
使用 ANTLR 生成代码
编写完成 ANTLR 的语法文件后,将 .g4 文件作为一项参数,运行 ANTLR,可生成对应的解析程序,并且默认生成 Java 代码。如果需要生成其他语言的代码,可以在运行 ANTLR 时通过 -Dlanguage= 来指定。

ANTLR 在完成语法分析后,会生成一棵程序对应的语法树。
遍历语法树
ANTLR 提供了 Listener 和 Visitor 模式完成语法树的遍历,默认生成的是 Listener 模式的代码,如果要生成 Visitor 模式的代码,需要在运行选项中加上 -visitor,如果要关闭生成 Listener 模式的代码,则需要运行选项中加上 -no-listener。
上面 ANTLR 会生成一堆程序,其中 calcLexer.java 是词法分析程序,calcParser.java 是语法分析程序。*.tokens 文件中包括一系列 token 的名称和对应的值,用于词法分析和语法分析。*.interp 包含一些 ANTLR 内置的解释器和需要的数据,用于 IDE 调试语法。
calcListener.java 和 calcVisitor.java 是 Listener 和 Visitor 模式的接口,而 calcBaseListener.java 和 calcBaseVisitor.java 分别对应接口的默认实现。在使用 ANTLR 生成的代码时,需要定义一个类继承 BaseListener 或者 BaseVisitor,在其中重写遍历到每个节点时所调用的方法,完成从语法树翻译到 IR 的翻译工作。能帮你到这里,已经是 ANTLR 仁至义尽了。
Listener 模式中为每个语法树节点定义了一个 enterXXX 方法和一个 exitXXX 方法,如 void enterExpr(calcParser.ExprContext ctx) 和 void exitExpr(calcParser.ExprContext ctx)。遍历语法树时,程序会自动遍历所有节点,遍历到一个节点时调用 enter 方法,离开一个节点时调用 exit 方法,需要在 enter 和 exit 方法中实现翻译工作。
Vistor 模式中为每个语法树节点定义了返回值类型为泛型的 visitXXX 方法,如 T visitExpr(calcParser.ExprContext ctx)。遍历语法树时,你需要调用一个 Visitor 对象的 visit 方法遍历语法树的根节点,visit 方法会根据传入的节点类型调用对应的 visitXXX 方法,你需要在 visitXXX 方法中实现翻译工作。在翻译工作中,你可以继续调用 visit 方法来手动遍历语法树中的其他节点。
我们可以发现:Listener 模式中方法没有返回值,而 Vistor 模式中方法的返回值是一个泛型,类型是统一的,并且两种模式中的方法都不支持传参。在我们需要手动操纵返回值和参数时,可以定义一些属性用于传递变量。
Listener 模式中会按顺序恰好遍历每个节点一次,进入或者退出一个节点的时候调用你实现的对应方法。而 Vistor 模式中对树的遍历是可控的,你可以遍历时跳过某些节点或重复遍历一些节点,因此在翻译时推荐使用 Visitor 模式。
在 IDEA 中使用 ANTLR
IDEA 中的 ANTLR 插件使得使用它的过程变得非常方便。首先,需要在 Settings/Plugins 中安装 ANTLR.v4 插件。
然后新建 maven 项目,并在项目的 pom.xml 中插入下面的代码,就可以愉快地使用 ANTLR 了。
1 | <dependencies> |
注意:版本号需要与你安装的版本一致。
接下来使用的过程就很白痴了。首先需要准备一个 .g4 文件(请自己书写),这里以我编译比赛自用的 .g4 文件举例。书写好后,右键单击该文件会出现 Configure ANTLR 的选项,在里面配置生成文件的路径等信息。
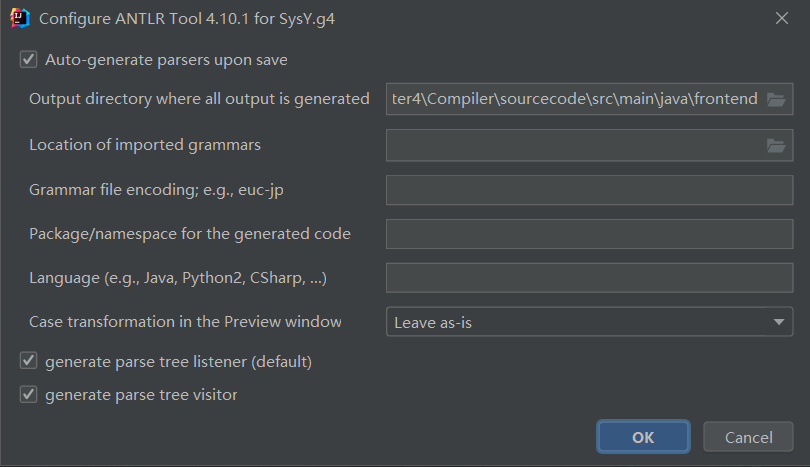
接着再单击 Generate ANTLR Recognizer 选项就会生成你所需要的一系列文件了。
在动手重写 Visitor 之前,你也有机会体验一下 ANTLR 的好玩之处。打开 .g4 文件,在顶层模块处右键单击 Run Rule Program,可以在线动态地生成由输入文件解析出的语法树(在调试与 debug 的过程中,它将长久地伴随着你……)。Enjoy!