
让人大致了解编译前端到底是在干什么——巧妇难为无米之炊嘛,同时因为我是搞前端的,犯懒的思想使得我没有把关于后端的内容看得太多,因此就不写出来误人子弟了。
一个常见的编译器大致分为三部分:前端、中端和后端(有些地方也将中端看作后端的一部分,而在编译比赛中,感觉中端很大程度上又是前端的一部分……总之是一个作为前后端桥梁的工作)。
- 前端:编译器前端会将源程序读入,在进行词法分析和语法分析以后将源程序转化为一棵抽象语法树(Abstract Syntax Tree,AST),并在此基础上对语法树进行扫描,对其进行语义分析,检查是否有语义错误。
- 中端:编译器中端会对 AST 进行扫描,并生成对应的一层或者多层中间表达形式 IR ,同时,对其进行优化。
- LLVM IR 就是一个拥有较活跃生态的中间表达形式
- 后端:编译器的后端通常会将 IR 转化为具体体系结构的汇编代码(MIPS,x86,arm,RISC-V……),并在这个基础上做一些面向体系结构的优化。
抽象地看,编译器由前端和后端组成,前端负责特定于语言的任务,读取源文件并计算语义分析表示,通常是带注释的抽象语法树 AST;后端从前端的结果创建优化的机器码。区分前端和后端的动机是可重用性。
前端和后端有特定的结构。前端通常执行以下任务:
- 词法分析器 Lexer:读取源文件并生成一个令牌流
- 解析器 Parser:从令牌流创建一个 AST
- 语义分析器向 AST 添加语义信息
- 代码生成器从 AST 生成一个中间表示(IR)
# 一些基本概念:AST & Lexer & Parser #
抽象语法树 (Abstract Syntax Tree, AST) :抽象语法树是源代码结构的一种抽象表示,它以树的形状表示语言的语法结构。抽象语法树一般可以用来进行
代码语法的检查,代码风格的检查,代码的格式化,代码的高亮,代码的错误提示以及代码的自动补全等等。语法解析器 (Parser) :语法解析器通常作为
编译器或解释器出现。它的作用是进行语法检查,并构建由输入单词(Token)组成的数据结构(即抽象语法树)。语法解析器通常使用词法分析器(Lexer)从输入字符流中分离出一个个的单词(Token),并将单词(Token)流作为其输入。实际开发中,语法解析器可以手工编写,也可以使用工具自动生成。词法分析器 (Lexer) :
词法分析是指在计算机科学中,将字符序列转换为单词(Token)的过程。执行词法分析的程序便称为词法分析器。词法分析器(Lexer)一般是用来供语法解析器(Parser)调用的。
中间表示 IR 是给后端的接口。后端执行以下任务:
- 后端在 IR 上执行与目标无关的优化
- 为 IR 代码选择指令
- 之后,对指令执行与目标相关的优化
- 最后,产生汇编程序代码或者目标文件
词法分析和语法分析
词法分析的作用是从左到右扫描源程序,识别出程序源代码中的标识符、保留字、整数常量、算符、分界符等单词符号(即终结符),并把识别结果返回给语法分析器,以供语法分析器使用。
语法分析是在词法分析的基础上针对所输入的终结符串建立语法树 ParseTree,并对不符合语法规则的程序进行报错处理。
通俗地说,就是词法分析将代码变成一个 Token 序列,而语法分析则根据这个 Token 序列携带的信息产生了一棵抽象语法树 -> 语法树是前端的最终结果。当然,如果是在编译比赛中,那么 IR 代码是前端的最终成果。
语义分析
如果语法分析的过程成功结束了,并且输出了一棵正常的 AST,只能说明输入的源程序符合文法,但一个符合文法的源程序并不一定是一个正确的源程序,而这种错误是无法在词法分析和语法分析中发现的。所以,编译器还需要对语法分析得到的语句进行分析,从而了解每个程序语句具体的含义,这个过程即语义分析。
值得注意的是,通过了语义分析的代码只能说对编译器而言是明确的,编译器的翻译工作能够继续进行下去,但仍不一定正确,比如未定义行为。
语义分析通常分为两个部分:分析符号含义和检查语义正确性。在实践中,语义分析还通常会和中间代码生成同时进行。分析符号含义指的是对于表达式中出现的符号,找出这个符号代表的内容,这个工作主要通过符号表来实现。检查语义正确性指的是检查每条语句是否合法,比如检查每个表达式的操作数是否符合要求,每个表达式是否为语言规范中所规定的合法的表达式,使用的变量是否都经过定义等。
总的来说,在这一阶段,需要对 AST 进行扫描(扫描次数由具体实现方式决定),并完成以下检查:
- 符号表构建:声明了哪些标识符,待编译程序使用的标识符对应于哪个位置的声明
- 类型检查:各语句和表达式是否类型正确
如果编译器在这个阶段发现了错误,那么通常整个编译过程在这一阶段结束以后就将终止,并且报告编译错误。
构建符号表
符号表是编译器编译过程中的一种特殊数据结构,通常用来记录变量和函数的声明以及其他信息。在分析表达式和语句的时候,如果这些表达式或者语句引用了某些标识符,我们可以在符号表中查询这些标识符是否有对应的定义或者信息。符号表的层次结构和作用域是一一对应的,这样做有利于查出符号是否有重定义,以及确定不同作用域引用的标识符。
类型检查
完成符号表建构后,我们就可以自顶向下地遍历 AST,对对应的节点进行类型检查。对于静态类语言,在语言设计之初,设计者都会考虑该语言支持表达哪些类型,并给出定型规则。在已知定型规则的情况下编码实现类型检查算法并不困难,往往只要逐条将其翻译为代码即可。
⭐编译器结构
编程语言
了解语言的构建可以更好地写出针对不同编程语言的编译器。
- 编译比赛采用的是 SysY2022 语言
指定编程语言语法的形式
语言的元素称为标记,比如关键字、标识符、字符串、数字、操作符等等。其实程序就是一个标记的序列,语法是用来指定哪些序列是有效的。
通常来说语法是用扩展巴克斯-诺尔范式(EBNF)编写的。
#一些基本概念 EBNF#
EBNF 是一种用于描述计算机编程语言等正式语言的,与上下文无关语法的元语法(metaSyntax)符号表示法。简而言之,它是一种描述语言的语言,是基本巴克斯范式 BNF 元语法符号表示法的一种扩展。
EBNF的基本语法形式如下,这个形式也被叫做production:
左式(LeftHandSide) = 右式(RightHandSide).
(lhs 和 rhs 的字眼将频繁地出现在你的代码中)
左式也被叫做 非终端符号(non-terminal symbol),而右式则描述了其的组成。
- 符号
下表是推荐标准 ISO/IEC 14977 所定义的符号:
2
3
- 终端符号(Terminal symbols):形成所描述的语言的最基本符号。所描述语言的标点符号 (不是EBNF自己的) 会被左右加引号 (它们也是终端符号) ,而其他终端符号会用**粗体**打印
- 非终端符号:是用于描述语法的变量,它必须被定义在一个 *production* 中。或说,它们必须出现在某个地方的 *production* 的左式中
约定
使用了如下约定:
- EBNF 的每个元标识符 (meta-identifier) 都被写为用连字符 (“-“,hyphens) 连接起来的一个或多个单词
- 以 “-symbol” 结束的元标识符是 EBNF 的终端符号
用普通字符表示的 EBNF 操作符按照优先级 (顶部为最高优先级) 排序为:
*repetition-symbol(重复符)
-except-symbol(除去符)
, concatenate-symbol(连接符)
| definition-separator-symbol
= defining-symbol(定义符)
; terminator-symbol(结束符)
. terminator-symbol(结束符)以下的括号对 (bracket pairs) 能够改变优先级,括号对间也有优先级 (顶部为最高优先级) :
’ first-quote-symbol first-quote-symbol ’ (* 引用 )
" second-quote-symbol second-quote-symbol " ( 引用 )
( start-comment-symbol end-comment-symbol ) ( 注释 )
( start-group-symbol end-group-symbol ) ( 分组 )
[ start-option-symbol end-option-symbol ] ( 可选 )
{ start-repeat-symbol end-repeat-symbol } ( 重复 )
? special-sequence-symbol special-sequence-symbol ? ( 特殊序列 *)

语法对编译器作者的帮助
- 首先,定义了所有标记,这是创建词法分析器所需要的,语法规则可以翻译成解析器。当然,如果出现关于解析器是否正确工作的问题,那么语法可以作为一个很好的规范
- 然而,语法并不是定义编程语言的所有方面,语法的意义 (语义) 也必须定义。为此目的也开发了语法形式,类似于最初引入该语言,通常在纯文本中指定
💻语法分析
正如上节所说,编程语言由许多元素组成,例如关键字、标识符等,而词法分析的任务就是获取文本输入并从中创建标记序列,一般来说,我们需要为每个令牌分配索引(数字)。
Example:calc 语言由 with、:、+、-、*、/、(, and) 标记和 ([a- za -z])+(标识符) 和 ([0-9])+(一个数字) 正则表达式组成,这每一种元素就是一个令牌,或者说 Token。
后面的举例都将以这个简单的 calc 语言为主。
[Lexer] 手写的词法分析 Lexer
词法分析程序的组件实现通常称为 Lexer。
在词法分析部分,我们们需要一个 Token 类和一个 Lexer 类。此外,需要一个 TokenKind 枚举来给每个令牌类一个的数字。拥有一体化的头文件和一个实现文件是无法扩展的,所以需要重构这些内容。
TokenKind 枚举可以复用,并放置在 Basic 组件中。Token 和 Lexer 类属于 Lexer 组件,但是放在不同的头文件和实现文件中。

令牌类 Token

-
一般来说,除了为每个令牌定义成员以外,还可以添加两个额外的值 eoi 和 unknown。eoi 表示 输入的结束(EndOfInput),如果处理完输入的所有字符,则返回 eoi;unknown 用于词汇错误的情况,例如,‘#’ 不是已定义的语言标识,所以会被映射为 unknown。
-
除了枚举 TokenKind 以指示读到的标识符的类型以外,Token 类还应该有成员Text,指向令牌文本的开头,用于指示读到的标识符名称。对于语义处理,知道标识符的名称很重要。

-
is() 和 isOneOf() 方法用来测试令牌是否属于某种类型

接口
一般来说,除了构造函数,Lexer 类的公共接口只包含 next(),用于返回下一个令牌。该方法的作用类似于迭代器,总会指向下一个可用的令牌,该类的唯一成员是指向输入开头和下一个未处理字符的指针,并且假设缓冲区以 0 结尾。

-
除了这些语法范围内的工作,还需要定义需要忽略的字符,比如空格或者新行等,next() 方法要跳过这些字符
-
由固定字符串定义的标记最好使用 switch 开关完成。对于只有一个字符的标记(比如那种运算符),可以使用 CASE 宏来减少输入(注意这个源教程是来自 C++ 的)

-
最后,需要定义一个 helper 方法填充 Token 实例的成员,并更新指向下一个未处理字符,就是要让指针一直往后移。
[Parser] 手写的解析器
语法分析由解析器完成,它的基础是语法和词法表。解析过程的结果是一个成为抽象语法树(AST)的动态数据结构,AST 是输入的一种非常浓缩的表现形式,非常适合语义分析。
一般来说,Parser 类里需要实例化 Lexer 和 Token。Token 存储下一个令牌(前置),而 Lexer 用于检索下一个令牌。再声明一个布尔值 HasError 用于指示目前是否检测到了错误。
也就是说:解析器是从语法派生出来的。让我们回顾一下所有的构造规则:对于每个语法规则,都要创建一个以规则左侧的非终结符命名的方法,以便解析规则的右侧。根据右边的定义,必须做以下事情:
- 对于每个非终结符,调用相应的方法。
- 处理每个令牌
- 对于可选组和可选组或重复组,将检查前瞻性令牌 (下一个未使用的令牌),以决定从哪里继续。
处理令牌


- advance() 从词法分析器中检索下一个令牌
- 在 Expect() 中测试,并提前检查是否为预期的类型,如果不是,则发出错误消息
- 如果是预期类型,consume() 检索下一个令牌。如果发出错误消息,则将 HasError 设置为 true
需要注意的一个问题是左递归规则。如果右边和左边以相同的终端开始,规则是左递归的。表达式的语法中可以找到一个典型的例子:
expression : expression “+” term ;

左递归也可能间接发生,涉及更多规则,这很难发现。这就是为什么存在一种可以检测和消除左递归的算法。
对于语法中的每个非终结符,需要声明一个解析规则的方法,最后才能串成一棵 AST。

它们是没有识别和编号的方法。这些规则只返回令牌,并替换相应的令牌。
对于公共接口,构造函数初始化所有成员并从解析器中检索第一个令牌。

深入分析解析器的实现

正如上一节所说,parse() 的要点是处理整个输入,并且使用特殊符号检查输入的结束。进入 parse() 以后,会进入 parseCalc(),然后再递归下降进入到 parse*() 中去,最后完成整棵 AST 的解析。
parse*() 方法的解析规则
所有的解析方法遵循的都是相同的解析模式,因此在这里我们以 parseCal() 为例仔细研究一下如何实现相应规则的解析。
首先回顾 calc 的规则:
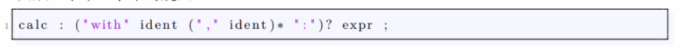
然后按照如下的规则解析:



吐槽一下:为啥要用 true 值表达 expectVar not found 呀!简直不符合人类逻辑(擦泪)
这很简单,不是吗? 当记住了使用的模式,就会发现基于语法规则编写解析器很刻板。这种类型的解析器称为递归下降解析器。
[ATTENTION] 递归下降解析器不能适配所有语法
语法必须满足某些条件才能适合构造递归下降解析器。这类语法叫做 LL。事实上,可以在网上找到的大多数语法都不属于这一类语法。不过应付毕昇杯和编译作业倒是足够了。
关于这个主题的经典书籍是“龙书”,也即由 Aho, Lam, Sethi 和 Ullman 编写的《编译器: 原理,技术和工具》。
错误处理 - 恐慌模式
检测语法错误很容易,但更重要的是从错误中恢复,一个简单的方法是“恐慌模式”。
-
恐慌模式下,将从令牌流中删除令牌,直到找到解析器可以使用的令牌才继续工作。大多数编程语言都有表示结束的符号,例如:C++,可以使用
;(语句的结束) 或}(块的结束)
-
另一方面,错误可能是正在寻找的符号不见了。这种情况下,许多标识可能在解析器继续之前就删除了,这并不像听起来那么糟糕
- 现今,编译器的速度非常重要。在出现错误的情况下,开发人员可以查看第一个错误消息,修复它,并重新启动编译器。这与使用穿孔卡片不同,在穿孔卡片中需要获取尽可能多的错误消息,因为等编译器运行完成就是第二天了。
[AST] 抽象语法树
解析的结果是 AST,是输入程序的另一种紧凑表示形式,捕获了程序的重要信息。AST 可以帮助删除语句中不重要但对解析器来说很重要的部分(比如分隔符),因为我们最终要将语句转换为内存中的表示,内存不关心这些东西。
对于上面举例的 calc 语言,AST 需要有以下的数据结构特征:

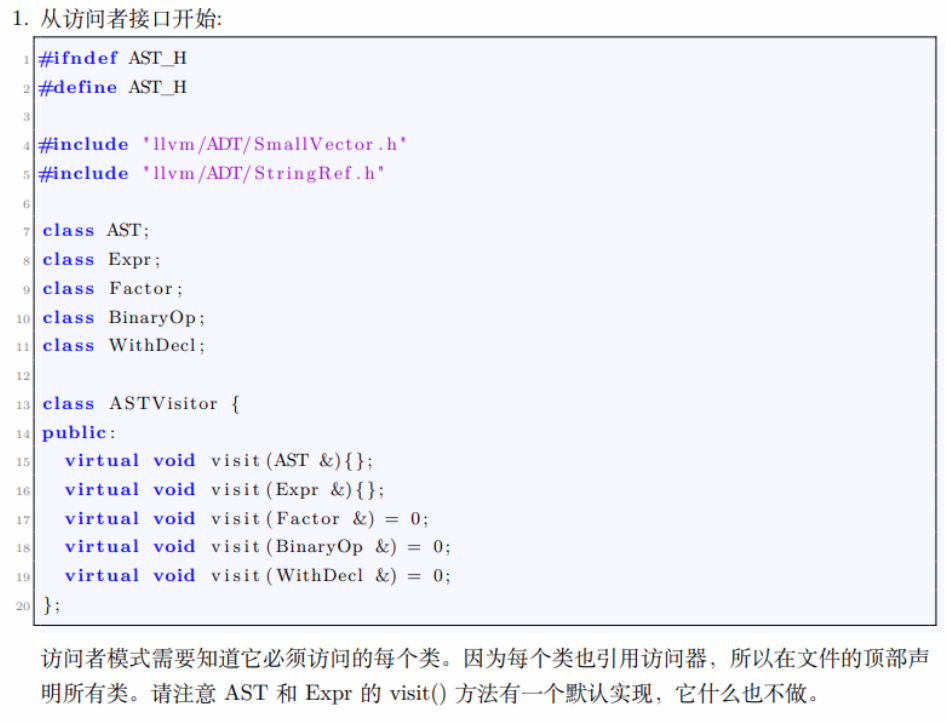



注意这个 访问者模式 的构造,最后我们编译器的实现也需要基于此。
AST 是在解析期间构造的。语义分析的过程就是检查树是否符合语言的含义(例如,声明使用的变量),并可能扩充树。之后,使用树来生成 LLVM IR 代码。
📕语义分析
语义分析遍历 AST 并检查语言的各种语义规则。例如:在使用变量之前必须声明变量,或者变量的类型必须在表达式中兼容。如果发现可以改进的情况,还可以输出警告。
对于表达式语言,语义分析器必须检查每个使用的变量是否声明,这是语言所需。一个可能的扩展是在未使用声明的变量时输出警告消息。
语义分析器一般在 Sema 类中实现,语义分析由 semantic() 执行。

语义分析的部分需要用前面在解析器中实现的访问者 Vistor 实现,其基本思想是,每个声明变量的名称存储在一个集合中,创建时,可以检查每个命名是否唯一,然后检查命名是否在集合中(感觉在 Java 中非常好实现)
语义分析跟解析器进一步融合在一起会如何呢?

下面依旧以 calc 语言举例子。注意,语义分析是基于 AST 的!需要关注树的节点。
- 与 Parser 类中一样,可以使用标记来指示发生了错误,这些名字存储在 Scope 的集合中。在持有一个变量名的 Factor 节点中,我们检查该变量名是否在声明变量的集合中。
- 对于 BinaryOp 节点,只需要检查两边是否存在,并且是否已经访问过。
- 在 WithDecl 节点中,填充集合并开始遍历表达式
- semantic() 方法会遍历树,并返回错误标志
- 对于没有使用声明的变量,也可以打印警告信息。
如果语义分析没有出现错误,那么就可以使用 AST 生成 LLVM IR 啦。
看到这里,谁不感谢 ANTLR 呢?(泪目)
AST 中使用 LLVM 风格的 RTTI
把所有的部分合一起前,需要理解使用 LLVM 风格的运行时类型信息 (RTTI)。
当然,AST 节点是类层次结构的一部分。声明总是有名字,其他属性取决于声明的内容。如果声明了一个变量,则需要一个类型。常量声明需要类型和值等。当然,在运行时需要找出使用的是哪种声明。为了实现这个,LLVM 开发人员引入了一种自制的 RTTI 风格。
层次结构的 (抽象) 基类是 Decl。要实现 LLVM 风格的 RTTI,需要添加包含每个子类标签的公共枚举。此外,还需要此类型的私有成员和公共 getter,私有成员通常称为 Kind。

(后面那两个网址就是 LLVM IR 的官方博客,有不少好东西)
编码工作的结果是一个修饰过的 AST,接下来的任务是使用它生成 IR 代码和目标代码。
🤩使用 LLVM 后端编译器生成代码
LLVM IR 的文本表示
详见 LLVM IR 笔记。这里就说基本块和 SSA 两件事。
IR 代码组织在基本块中。结构良好的基本块是指令的线性序列,它以可选标签开始,以终止指令 (例如,分支或返回指令) 结束。因此,每个基本块都有一个入口点和一个出口点。LLVM 允许在构造时出现畸形的基本块。
IR 代码的另一个特点是 SSA 形式的。代码使用无限数量的虚拟寄存器,但每个寄存器只编写一次。比较的结果分配给指定的虚拟寄存器 %cmp。这个寄存器随后会使用,但它永远不会再写入。诸如常量传播和公共子表达式消除之类的优化在 SSA 表单中工作得非常好,所有现代编译器都在使用它。
IR 代码本身看起来很像 C 语言和汇编语言的混合。
使用 AST 生成 IR
一般通过一个 CodeGen 类来实现。因为 AST 包含了语义分析阶段的信息,所以基本思路是使用 Vistor 来遍历 AST。
大概就是:
- 实现 Visitor
- 用 Visitor 遍历 AST
- 调用 LLVM 库不断生成 IR
基本是通过重写 Visitor 类来完成。结合一个合乎常理的 CompileDriverRaw 程序就可以把 IR 代码输出(当然具体的 IR 信息都保存在整个 Module 的函数符号表里了,需要的时候调用就可以),这部分灵活性很大,因此没有什么可供展示的代码细节。在这里我贴一下自己的测试程序节选,大概可以让读者了解是个怎样的输出过程。
1 | public class CompilerDriverRaw { |
这样一来,就实现了编译器的前端,从读取代码到生成 IR。Congratulations!
当然,所有这些组件必须在用户输入时协同工作,这是编译器驱动程序的任务,现在还需要实现运行时所需的功能。
驱动程序和运行时库
使用一个文件来把前几节的所有阶段驱动程序合在一起,最后调用代码生成器 CodeGen,这样就成功地为用户输入创建了 IR 代码。我们将目标代码的生成委托给 LLVM 静态编译器 llc,这样就完成了编译器的实现。
然后再搞一个文件把所有组件链接到一起,创建运行时库。一般来说是创建一个应用程序,它可以从输入文本创建 IR,而 LLVM 静态编译器将 IR 编译为一个目标文件。然后,可以使用自己喜欢的 C 编译器链接到小型运行时库——这样就创建了一个基于 llvm 的编译器。
补充内容
组件依赖关系
根据前面的内容,我们知道需要实现词法分析器、解析器、AST 和语义分析器,它们的组件分别是 Lexer、Parser、AST 和 Sema。
组件有明确定义的依赖项。一般来说,Lexer 只依赖于 Basic。Parser 依赖于 Basic、Lexer、AST 和 Sema。最后,Sema 只依赖于 Basic 和 AST,这些定义良好的依赖有助于对组件的重用。