
项目仓库地址:ybNo1/blislab: BLISlab: A Sandbox for Optimizing GEMM
首先需要注意两点:
-
blislab 的代码是列主序的。
-
引入了 主元的跨度 (leading dimension,ld)这个概念。
C(i, j)的含义是C[j * ldc + i],如下图所示: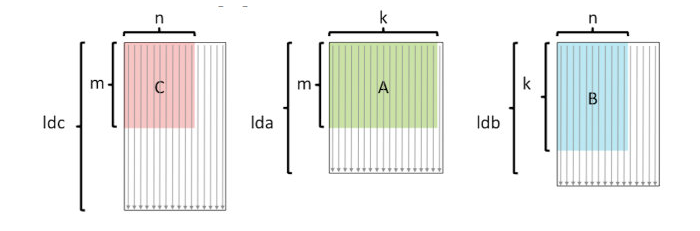
以列主元为例,说明跳到下一列的时候不应该 + m,而是 + ldc。
step1:基础优化
从数学原理的角度观察,跟最朴素的矩阵乘没区别。
1 | /* |
通过阅读源码,可知采用了如下的基础优化技术:
使用指针取代对地址的直接计算
使用指针前:
1 | for ( i = 0; i < m; i ++ ) { |
使用指针后:
1 | double *cp; |
循环展开
本质上是在朴素矩阵乘法的基础上做一个基础的分块,其中,MR 和 NR 约束了分块的规模,缺省时是 1 x 1 ,也就是没有分块。
可以看到,AddDot 函数中看似冗杂的运算其实是重复利用读取的 a 和 b,把中间结果保存在寄存器里。
但这一层次的复用只是针对寄存器做的分块(也就是复用读取到寄存器的数据),矩阵规模变大了之后,子矩阵规模可能也超过了 cache 的大小,导致很严重的 cache miss 。
step2:针对多级 cache 的分块
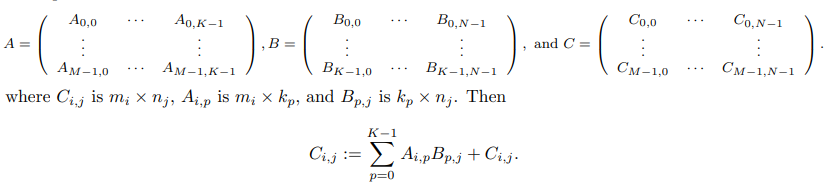
基于 step1 寄存器分块的缺点,提出对分块优化的更高要求:操纵 cache(也就是 cache 分块)。如果想要达到这个目标,就需要讨论:
- 哪些数据放到 cache 中
- 将 cache 中的哪些数据替换出去
但实际上我们不能像“操纵”寄存器那样 —— 通过写一些限定代码让这一段数据在寄存器中被操作 —— 来操纵 cache ,本质是 CPU 不能被直接操纵。因此我们做一些 tradeoff ,间接完成类似的效果:
- 使用 pack 函数(打包函数)
- 含义是将不连续的数据 copy 到连续的内存中,之后从连续的内存读取数据,进而利用硬件上采用的一些替换算法提高分块的访存性能,减小 cache miss
- 需要额外申请一块缓冲区
- 使用 Z 字型做排列(至于为什么是 Z 字型,跟条带分割的算法有关)
- 某些芯片可以使用 预取指令 (prefetch),让一些数据提前被读到 cache 里
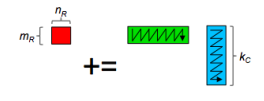
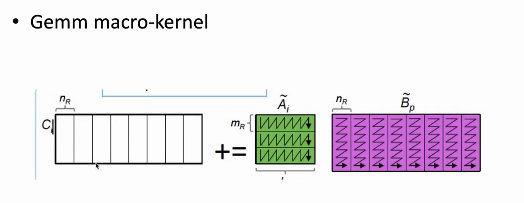
此处还不得不考虑一个问题:cache 的读取是以 cache line 为单位的,也就是说存在 对齐 的需求。在对齐的情况下更能发挥内存带宽等处理器性能。这一步可以通过调整申请的 buffer 的规模来控制。
1 | /* |
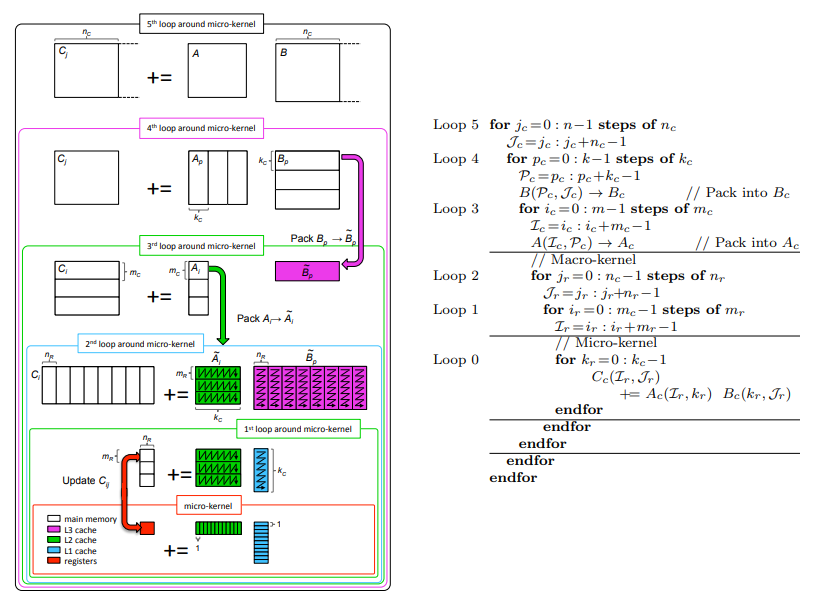
BlisLab 的 tutorial 中用了一张比较吓人的图说明 GotoBLAS 中针对三级 cache 使用的分块算法(以及排流水的 Piping 过程):
不过,如果使用 GPU 的话,程序员可以通过软件操控 cache ,这里就可以使用很多数据搬运的 tricks,例如从 global memory 搬运到 shared memory,从 shared memory 搬运到寄存器等。只不过这种手动控制的编程复杂度很高。
一个常用的 GPU 编程优化点叫做 双缓冲优化 ,其一般流程是:
双缓冲的过程体现在将 shared memory 一分为二,一半用于做本次运算,一半用于做下一次传输,DMA 的数据传输与内核的运算过程重叠,以平滑多级存储结构的数据传输,让内核始终以峰值速度运行 —— 跟 prefetch 的作用基本上一样。
step3:并行化
基本上就是 基于 SIMD 的向量化编程 工作,需要讨论中间结果在寄存器中如何排布 / 如何使用合适的汇编指令计算等的问题。了解了对应体系结构的汇编指令细节之后就没什么问题。
例如,光两个 4 x 1 向量相乘得到结果矩阵的 “一层” 的问题,就有两种汇编指令解决方案:直接 Broadcast 模拟向量乘法,或者使用蝶式排列(Butterfly Permutation),如下所示。
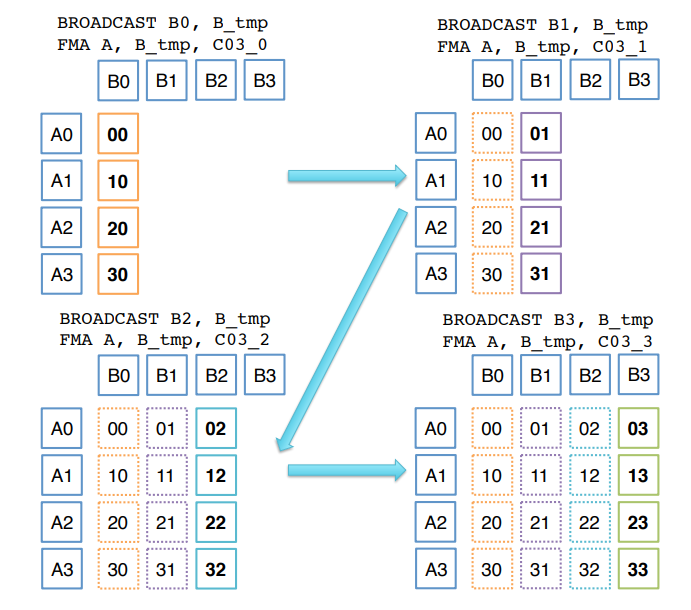
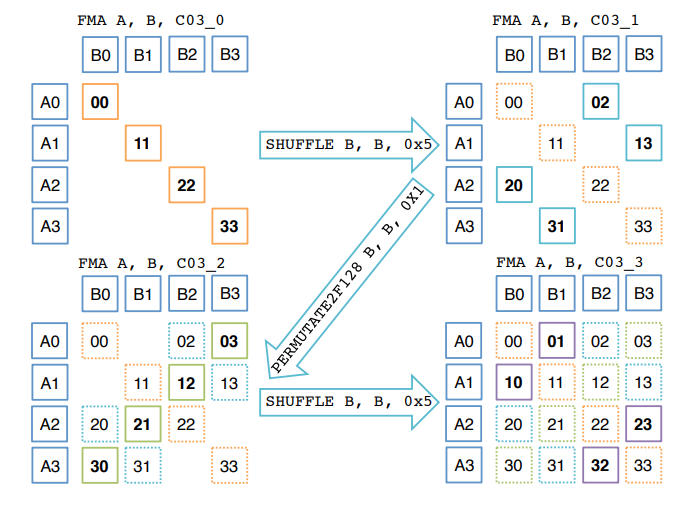
P.S. 体系结构中有许多种互连函数,包括蝶式函数、均匀洗牌函数、反位序函数、PM2I 等。
- 参考:
- N. H. F. Beebe, et al. “High-Performance Matrix Multiplication,” Feb. 1970.
- 张先轶, et al. “OpenBLAS:龙芯3A CPU 的高性能BLAS 库.”
- BLISlab: A Sandbox for Optimizing GEMM, https://github.com/ybNo1/blislab/tree/master