
依旧是因为工作需要进行的调研(究极抱佛脚 🤡 感觉很多计组和操作系统的知识都忘得差不多了 ……
以及,感谢善良的小刺猬老师收留无能的我。
多核 CPU 和多线程技术
- 处理器速度的测量单位:每秒执行百万条指令数(MIPS)
先进的 CPU 处理器
如今,先进的微处理器芯片都采取双核、四核或者更多处理核心的 多核体系结构 。“多核” 表征了计算机能够同时处理多条指令的水平,一个 n 核心的处理器最多可以同时执行 n 条指令。每个核心都可以独立执行一条指令,因此在同一时刻,处理器可以同时执行的最大指令数等于核心数。
多核体系结构是指计算机系统中具有多个处理核心(也称为核)的架构。每个核心都是一个独立的处理单元,可以执行独立的指令流,并且能够同时处理多个任务。这些核心可以共享一些资源,如内存和缓存,但也可以有各自独立的资源。核心的本质是一个拥有私有 cache 的处理器,多核与被所有核心共享的 L2 cache 布置在同一块 CPU 芯片上。
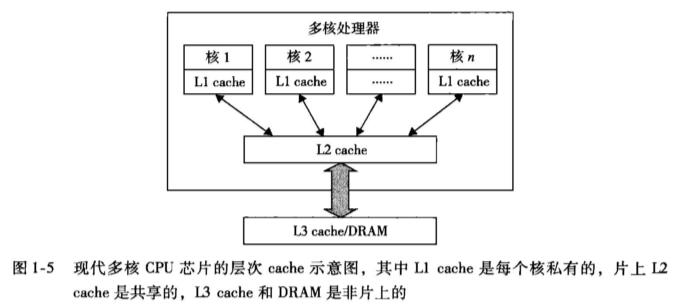
显然,多核体系结构的优点包括:
- 提高计算机系统的性能:多核处理器可以同时执行多个任务,从而提高系统的整体性能和响应速度。
- 提高系统的并行处理能力:不同的核心可以并行地执行不同的任务,从而提高系统的并行处理能力。
- 提高能源效率:多核体系结构可以在相同的功耗下执行更多的任务,从而提高能源的利用效率。
这一优越的性能带来了程序设计或系统管理层面上的并行性设计挑战。为了充分利用多核处理器的性能,我们往往需要将任务分解为可以并行执行的子任务,并进行合理的调度和同步,以避免冲突和竞争条件,影响程序运行的正确性甚至系统的安全性。
并行度(Degree of Parallelism)
目前的处理器大多在 ILP 或者 TLP 级别上开拓并行。ILP 和 TLP 是两个并行度的概念,并行度历经了 BLP → ILP → DLP → TLP → JLP 的探索过程,其中:
- BLP(Bit-Level Parallelism,位级并行)
- 几十年前的计算机采用位串行方式,在这个场景中,位级并行将位串行处理过程转变成了字级处理,我们常听说的 64 位处理器、32 位处理器指代的是硬件的字长,同时也指代了处理器位级并行的水平
- ILP(Instruction-Level Parallelism,指令级并行)
- 指的是在程序执行过程中,指令之间可以并行执行的程度,处理器同时执行多条指令而不是一个时刻执行一条
- 提高 ILP 级别可以通过硬件技术(如超标量处理器、乱序执行等)或编译器优化来实现
- ILP 在现代处理器中已经得到了充分开拓,其机制包括多路超标量体系结构、动态分支预测、猜测执行、VLIW(Very Long Instruction Word, 超长指令字)等方法
- 指的是在程序执行过程中,指令之间可以并行执行的程度,处理器同时执行多条指令而不是一个时刻执行一条
- DLP(Data-Level Parallelism,数据级并行)
- 这个概念的流行源于 SIMD(Single Instruction,Multiple Data,单指令多数据)和使用向量与数组指令类型的向量机,需要更多的硬件支持和编译器辅助来实现
- TLP(Task-Level Parallelism,任务级并行)
- 多核处理器和片上多处理器(Chip MultiProcessor,CMP)引入后,进行了任务级并行的探索,与 BLP、ILP 和 DLP 相比还不是很成功
- TLP 级别越高,表示程序中的多个 线程 可以更好地利用多核处理器或多处理器系统的资源,从而提高程序的执行效率
- 提高 TLP 级别可以通过多线程编程、并行算法设计等方式来实现
- TLP 和 DLP(数据级并行)在 GPU 上被充分探索,因为 GPU 采用 成百上千的简单核心 的 众核体系结构
- JLP(Job-Level Parallelism,作业级并行)
- 随着并行处理向分布式处理转移,产生的粗粒度并行方法
从多核 CPU 到众核 GPU 体系结构
学习过组成原理后,我们知道处理器硬件存在著名的 “内存墙” 问题 —— 内存墙指的是内存性能严重限制 CPU 性能发挥的现象。 在过去的 20 多年中,处理器的性能以每年大约 55% 速度快速提升,而内存性能的提升速度则只有每年 10% 左右。长期累积下来,不均衡的发展速度造成了当前内存的存取速度严重滞后于处理器的计算速度,内存瓶颈导致高性能处理器难以发挥出应有的功效,这对日益增长的高性能计算形成了极大的制约。
这主要归因于基于 CMOS 的芯片能量的限制,高频或高电压下额外热量的生成使得时钟速率已经达到了极限。目前,极少数的 CPU 芯片达到了 5GHz 以上的时钟速率。
“内存墙” 限制表明更多核心的处理器并不一定会带来更高的处理性能。SNL 的仿真测试结果表明:由于“内存墙”的制约,超过 8 核心之后,处理器性能几乎没有提升,而 16 核处理器的性能甚至不升反降。由此可见,随着处理器核心的不断增多、处理性能的不断提升,“内存墙”产生的瓶颈效应对基于多核处理器的高性能计算的制约将日趋严重。实际上,这导致 CPU 已经达到了大规模 DLP 开拓的极限。
因此,人们转向了有数百或更多轻量级核心(相对而言,CPU 具有的是重量级核心)的众核 GPU 的开发。在 Top500 系统中,许多 RISC 处理器已经被替换为多核 x86 处理器和众核 GPU。
总地来说,CPU 的设计风格是 面向延迟 的,而 GPU 是 面向吞吐量 的。
CPU 的优化设计目的主要是为了提高串行代码的性能、尽量缩减单个线程的执行时间。用于存储经常访问的数据、从而缩短内存访问延迟的大容量缓存,低延迟算术单元,高效但复杂的操作数传输逻辑 …… 这些优化消耗了大量的芯片面积和功耗,从而减少了算数运算单元和内存访问通道,但大大减少了延迟时间。
GPU 则不尽然,它通过支持流水化的存储器通道和允许较长的算术运算延迟,节省了大量的芯片面积和功耗,用来增加更多的器件,以提高整体吞吐量。执行多线程应用程序时,硬件可以充分利用因等待访问内存或进行算术运算而产生较长延时的大量线程,减少控制逻辑中需要执行的线程,简化控制逻辑。
异构与异构计算
这里简单提及一下异构的概念。很显然,异构的动机实际上是结合 CPU 优越的串行执行性能和 GPU 的并行计算效率,异构计算的目标是通过将不同类型的计算设备组合在一起,以提高计算系统的性能、效率和能力。这种计算方法可以根据任务的特点和要求,选择最适合的计算设备来执行不同的计算操作。
在异构计算中,常见的计算设备包括善于串行高效地执行通用计算任务的中央处理器 CPU 、善于并行计算和图形处理的图形处理器 GPU 、协处理器(如低能耗、可重构性好的 FPGA )等。通过将不同类型的计算设备组合在一起,异构计算可以充分利用各种设备的优势,提高计算速度和效率。
异构计算还可以通过任务划分和负载均衡等技术,将不同类型的计算任务分配给最适合的计算设备,从而进一步提高计算系统的整体性能和能力。
多线程技术
了解一些典型的指令调度模式:
- 只有同一个线程的指令才能在一个超标量处理器上执行
- 细粒度多线程处理器在每个时钟周期切换不同线程上指令的执行
- 粗粒度多线程处理器在切换到下一个线程前在相当多的指令周期内执行同一个线程的多条指令
- 多核 CMP 的多个核分别从不同的线程执行指令,对于每个核而言,情形与相同路数的超标量处理器相同
- 并发多线程处理器允许在一个时钟周期内同时调度不同线程的指令
这些模式概括了现代 CPU 处理器的 5 种微体系结构分别通过多核和多线程技术支持 ILP 和 TLP 的过程。可以可视化为下面这张图:
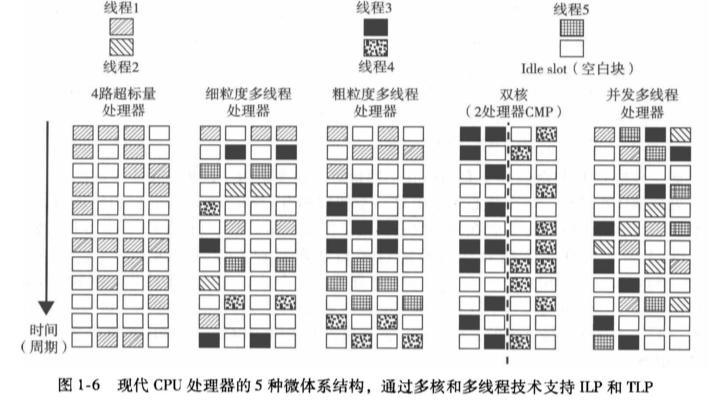
空白块的个数指示了处理器的调度效率。每个时钟周期内空白块个数的不一致则表明,实际上很难达到每个处理器周期内的 ILP 最大化或者 TLP 最大化。
大规模和超大规模 GPU 计算
GPU 顾名思义,一开始被开发出来是为了绘制图形,作为将 CPU 从繁重的图形任务中解脱出来的图形协处理器。图形任务的特点是单一子任务耗时短、非常简单,但是需要同时执行大量的单一子任务(例如,基于某个视频渲染需求,在一秒钟内绘制 1000 万个多边形),因此被针对性设计出来的芯片硬件 GPU 具有 慢速执行多并发线程 的大规模并行吞吐体系结构,而不是像 CPU 那样快速地执行一个单独的长线程。
与只由几个核构成的传统 CPU 相比,一个现代 GPU 芯片集成了至少数百个处理核心,而且现代的一些 GPU 在每个核心上还可以处理多个指令线程。做一个简单乘法可以得到,一个 GPU 上最多可以同时执行上千个线程,实现真正的大规模并行 —— 如今,它们被设计用于处理大批量的并行浮点运算等,支持海量数据并行处理,这在某种程度上让 CPU 摆脱了所有的数据密集型计算。
现代 GPU 体系结构基础
首先需要了解 CUDA 技术。CUDA(Compute Unified Device Architecture)是由 NVIDIA 开发的并行计算平台和编程模型。它允许开发者使用 C/C++、Fortran 等语言来编写并行计算程序,以在 NVIDIA 的 GPU 上进行高性能计算。CUDA 提供了一套丰富的库和工具,以帮助开发者利用 GPU 的并行计算能力。其中包括 CUDA C/C++ 编译器、CUDA Runtime API、CUDA Driver API 等。开发者可以使用这些工具来编写 CUDA 程序,并通过在主机上运行的 CPU 与在 GPU 上运行的并行计算任务之间进行数据传输和协调。
这里需要提及一下 GPGPU 的概念。GPGPU(General-purpose Programming using a Graphcis Processing Unit,基于 GPU 的通用编程),顾名思义,指调用 API 函数访问处理器内核,以为图形芯片编写应用程序的技术,例如我们熟悉的 OpenGL、Direct3D 等。显然,CUDA 就是 NVIDIA 提供的用于实现 GPGPU 的编程平台和工具。
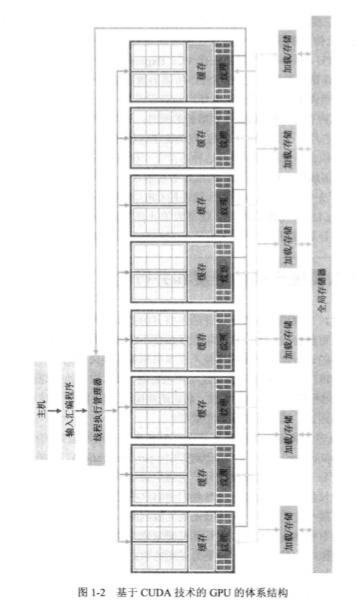
典型的现代 GPU 体系结构是基于 CUDA 技术的。这种体系结构由一个高度线程化的多核流处理器(Streaming Multiprocessor,SM)阵列组成,多个 SM 组成一个构建块。每个 SM 中又包含多个流处理器(Streaming Processor,SP),它们之间共享控制逻辑和指令缓存。
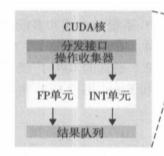
这张图展示了一个典型的 SP 结构,一个 SP 又被称为一个 CUDA 核心 。可以看到,它具有一个简单的可用于并行的流水线式整型运算器和浮点运算器。
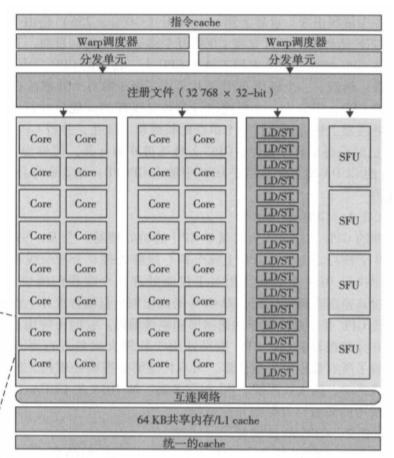
这张图则展示了一个典型的 SM 结构,可以看到,它具有 32 个 CUDA 核心,16 个用于每个时钟周期 16 个线程计算源和目的地址的读写单元,还有 4 个用于执行超越指令的特殊功能单元 SFU。所有的功能单元和 CUDA 核心都通过 NoC(Network on Chip,片上网络)内联于大量的 SRAM 存储(前面提到过的 L2 cache)。
每个 GPU 都带有若干 GB 的图形双数据速率(Graphics Double Data Rate,GDDR) DRAM ,被称为全局存储器。它们主要是用于图形处理的帧缓存,跟 CPU 中安装在主板上的系统 DRAM 不同,具有延迟较长但高带宽的特性。
整个体系结构拼起来大致如下图所示。
- 参考:
- 《大规模并行处理器编程实战 原书第二版》
- 《云计算与分布式系统 :从并行处理到物联网》