
上下文不敏感分析的问题
首先通过一个引例说明上下文不敏感分析存在的问题:
1 | void main() { |
针对这个程序做常量传播,考虑 i 的赋值语句处 i 的取值。对该程序进行上下文不敏感的指针分析,可以得到如下的一个 PFG:
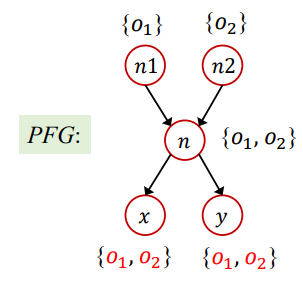
PFG 为 x.get() 解析出了两个目标方法,其中一个为 false positive,因此在常量传播算法中会将 i 定义为 NAC ——显然,这是不精确的。
错误的原因在于,我们在分析中不区分上下文,导致对于 id 方法的所有调用都会汇聚到一个点,从而丢失了精度,造成后续指针的指向集合中存在 false positive。但如果进行上下文敏感的温习,最终得到的 PFG 就会是下面这样:
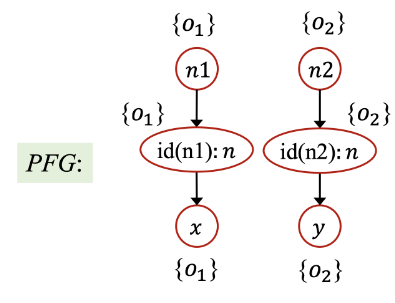
分析精度大大提高了。
上下文不敏感与上下文敏感
展开来说,上下文不敏感分析的精度丢失主要是因为下面这些原因:
- 在动态执行过程中,某一个方法可能在不同的调用语境中被调用了多次
- 在不同的调用语境中,方法中的变量可能指向不同的对象
- 在上下文不敏感的指针分析中,不同的上下文被混合到了一起,并传递给程序的其他部分,导致虚假的数据流
而上下文敏感则通过 区分不同调用语境 下的不同数据流来模拟调用上下文,进而提高分析精度。最为人熟知的上下文敏感建模策略是 调用点敏感 (call-site sensitivity:call-string),它使用一连串的调用点来表示上下文,即:本方法调用点 → 调用者的调用点 → 调用者的调用点的调用点……可以看出这就是对动态执行过程中调用栈的抽象。
实现上下文敏感最直接的方法是 基于克隆的上下文敏感分析 (Cloning-based Context-sensitive Pointer Analysis),它满足以下三个条件:
- 每个方法都被一个或者多个上下文修饰
- 变量也被上下文修饰,其上下文继承自声明该变量的方法
- 对于每个上下文,都恰有一个方法及该方法中的变量的克隆。也即:本质上每个方法及其中的变量都会被克隆,在每个上下文中分别克隆一次
上下文敏感的堆
在讨论上下文不敏感指针分析的时候,我们讨论过指针分析的四大关键因素,其中包括堆抽象。当时提出的堆抽象策略是分配点抽象,将同一分配点处产生的所有对象抽象成一个对象。实行了上下文敏感分析后,分配点处的变量已经上下文敏感,因此分配点处分配的堆内存也应该是上下文敏感的(将上下文敏感应用到堆抽象中),这样可以细化堆内存抽象的粒度,从而提高指针分析的精度。
面向对象程序(例如 Java)是典型的堆密集型语言。
-
抽象的对象也应当用上下文来修饰(称为堆上下文),最普遍的策略是 继承 该对象分配点所在方法的上下文
-
上下文敏感的堆抽象在分配点抽象的基础上提供了一个粒度更精确的堆模型
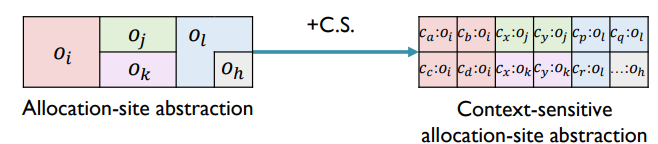
在动态执行过程中,一个分配点可以根据不同的调用上下文产生不同的对象。而即使在相同的分配点被分配,不同的对象也可能会携带不同的数据流被操作(例如在字段中存储不同的值),在指针分析中,不带堆上下文分析这样的代码可能会由于合并不同上下文中的数据流到同一个抽象对象中而丢失精度。相比之下,通过堆上下文来区分同一个分配点的不同对象则能够提升不少精度。
注意堆上下文是由于调用上下文产生的。
上下文敏感的指针分析规则
首先引入一些记号:
- 上下文:
- 上下文敏感方法:
- 上下文敏感变量:
- 上下文敏感对象:
- 字段:
- 实例字段:
- 上下文敏感指针:
- 指向关系:
- P() 表示幂集
然后定义分析规则如下:
- New:
i: x = new T() - Assign:
x = y - Store:
x.f = y - Load:
y = x.f
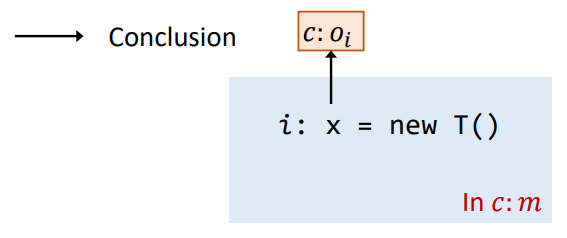



可以看到就是为之前的上下文不敏感分析规则部署了上下文修饰信息。而调用语句的变更则要复杂一些,因为调用语句除了在原本上下文不敏感的规则之上增加上下文,还需要负责被调用者上下文的生成,此处使用一个 Select 函数来表示调用者根据调用点处的信息生成被调用者上下文 的过程。

-
:基于调用点 处提供的信息为目标方法 m 选择上下文,即目标上下文的生成函数
-
其输入是调用点 、调用点处的上下文 、接收对象
-
输出是目标方法的上下文
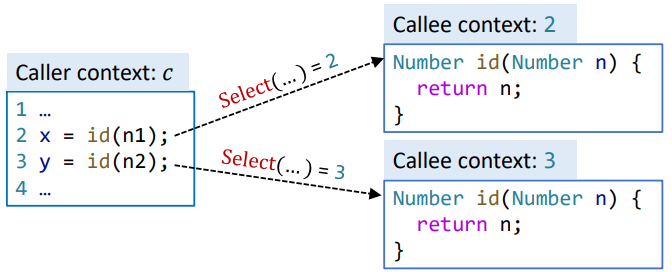
-
可以看到方法调用前后上下文被更新。
上下文敏感的指针分析算法
上下文敏感指针分析算法的使用与不敏感的过程类似,是一个构造上下文敏感的指针调用图(PFG with C.S.) + 在指针调用图上传播上下文敏感的指向关系的相互依赖的动态构造过程。此处,需要更新 PFG 的定义如下:
- 结点:
- 一个结点 n 表示一个上下文敏感的变量或者一个上下文敏感抽象对象的字段
- 此时指针被上下文修饰
- 边:
- 一条边 意味着被指针 x 指向的对象可能流到指针 y(也即可能同时被指针 y 指向)
- 此处的指针包含上下文信息
可见对于 PFG 上的结点以及指向集合中的对象,我们都会用上下文对其修饰以区分。不同修饰下的变量或者对象都有单独的一份克隆。
过程间上下文敏感的全程序指针分析算法

可以发现,这个算法只是在上下文不敏感算法的基础上增加了上下文敏感的内容(即在指针和对象之前加上了上下文的修饰,并在调用语句的处理中增加了新上下文的生成部分,即 Select)。需要注意的是入口方法的上下文被设置为空,因为一般情况下程序只有一个入口。
上下文敏感性:变体
本节将详细讲解分析算法中的一个抽象: Select ,并基于不同的 Select 函数描述几个上下文敏感性的变体:调用点敏感、对象敏感和类型敏感。
我们将前面提到的 定义为一个 上下文生成子 (Context Generator),并用其来定义一个指针分析的上下文敏感性。它描述了实例方法调用的时候应该用怎样的上下文修饰目标方法。 Select 函数是从调用者上下文到被调用者上下文的一个映射。
如果对于不同的输入, Select 函数给出了相同的输出,则称这种现象为 上下文重叠 (Context Overlap)。如果 Select 输出的目标方法的上下文和该方法所有现有的上下文不同,则称发现了一个新的上下文敏感的可达方法,否则将其和现有的同名且同上下文的方法合并。
可以看到:
- 如果
Select经常发生上下文重叠,则指针分析的精度↓,速度↑ - 如果
Select偶尔出现上下文重叠,则指针分析的精度↑,速度↓
基于这些定义,我们形式化地定义出分析的上下文敏感性如下:
下面讨论几种不同的 Select 函数(即上下文敏感性的变体),比较其精度和速度的区别。
调用点敏感
定义调用点敏感(Call-Site Sensitivity,也称调用串敏感 Call-String Sensitivity):
(更新上下文)
直接在实践中使用这个 Select 函数会产生问题。考虑递归调用,由于分析递归调用的时候是流不敏感的,因此不会有什么 Base Case,一旦遇到递归,此函数就会构造出无穷的调用串,导致指针分析算法无法终止。
因此,我们会对调用串的长度做出限制,以保证指针分析的算法能够终止。具体操作是为上下文的长度设置一个上限 。
- 对于调用点敏感,每个上下文都由调用串的最后 k 个调用点组成
- 实际操作中 k 是一个小数字,通常不大于 3
- 方法上下文和堆上下文可能使用不同的 k
根据这个限制,可以定义 k-调用点敏感(k-Call-Site Sensitivity,也称 k-控制流分析:k-CFA):
对象敏感
对象敏感中的上下文由一组抽象对象(由它们的分配点表示)组成。定义对象敏感(Object Sensitivity,也称分配点敏感 Allocation-Site Sensitivity):
- 在方法调用的时候,使用接收对象以及接收对象的堆上下文作为被调用者的上下文
- 根据不同的对象来区分不同的数据流操作,因为流动的数据一般都是由对象携带的
理论上说,调用点敏感和对象敏感的精度是没有可比性的。但在实际中(可以自己写一个程序手推),对于面向对象语言分析(如 Java),对象敏感的精度通常表现得比调用点敏感要好。不过有些时候调用点敏感也会比对象敏感更精确,因为同一个接收对象在不同的调用点处的被调用函数上下文其实也不同。
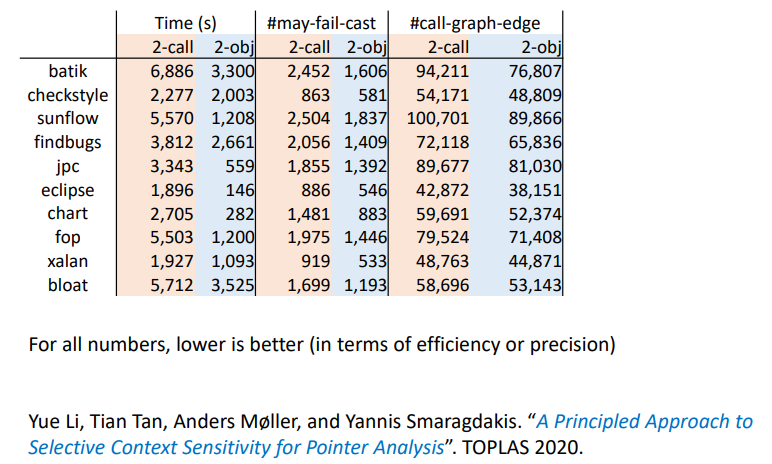
In general: In both precision and efficiency, object > call-site
类似调用点敏感,我们可以通过限制上下文的尺寸来避免由于递归导致的分析不终止问题,还能通过牺牲一部分精度提高效率。定义 k-对象敏感(k-Object Sensitivity):
类型敏感
针对类型敏感,每一个上下文都由一串类型组成。在方法调用处,用 接收对象的分配点所在类 以及该对象的堆上下文作为被调用者的上下文。它是对对象敏感的一种更粗糙的抽象(用接收对象分配点所在类代替接收对象,因而将同一个类型中的各个分配点在上下文中合并了),它通过牺牲对象敏感精度的方式换取了更好的性能。类似地,可以定义 k-类型敏感(k-Type Sensitivity):
其中, 表示 在哪个类中被创建。
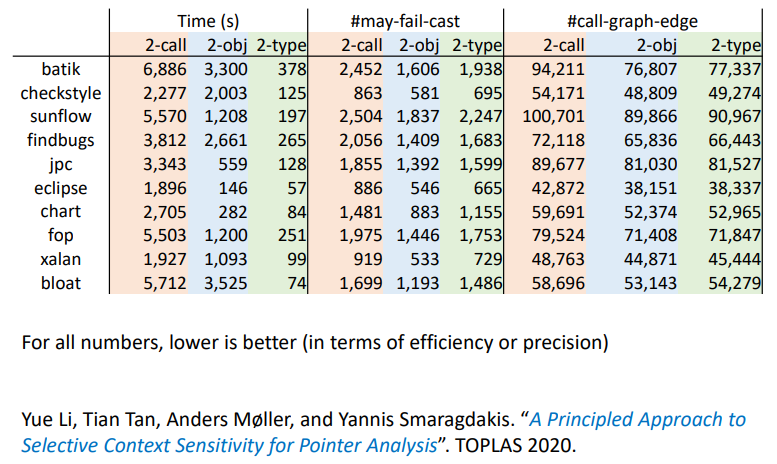
在面向对象语言的时间过程中,通常:
- 精度:对象敏感 > 类型敏感 > 调用点敏感
- 效率:类型敏感 > 对象敏感 > 调用点敏感