
链接汇总
⭐官方文档及 Tutorials:Welcome to Triton’s documentation! — Triton documentation (triton-lang.org)
官网介绍:Introducing Triton: Open-source GPU programming for neural networks (openai.com)—
⭐Github 仓库:openai/triton: Development repository for the Triton language and compiler (github.com)
⭐不需要 GPU 也能运行的 Triton 算子练习题:srush/Triton-Puzzles: Puzzles for learning Triton (github.com)
Tutorial Recommendations:OpenAI Triton Course/Tutorial Recommendations : r/OpenAI (reddit.com)
专家看点:谈谈对 OpenAI Triton 的一些理解 - 知乎, Triton 学习笔记
其他教程:
- OpenAI Triton MLIR 第一章 Triton DSL - GiantPandaCV 对算子书写和性能调优的一个简单概括
- Getting Started - Triton Exercises 应该是自己做的一套 Tutorials,内容有点 out-of-date 但很细致,可以用来了解一下原理
- Understanding the Triton Tutorials Part 1 | by Isamu Isozaki | Medium 包含 2 章对官方 tutorials 的分析,非常细致
- Exploring Triton GPU programming for neural networks in Java (openjdk.org) 可以只看 Triton 那一节,Oracle 专家的博客,非常简明扼要,重点突出
Triton 的目标
其实具体的 API 使用在文档中都已经描述得比较清晰了,所以这边先简单谈谈对 Triton 目标的理解。
首先 Triton 当然不能被简单概括成低配版 CUDA。它的定位更靠近 AI 编译领域,但与 TVM 或 XLA 这样的 AI 编译器亦有所不同。如果说 TVM 和 XLA 是纯粹的 AI 编译器,那么 Triton 更像是为 AI 加速器开发算子的领域特定语言(DSL, domain specific language)。为了将用户使用 Triton 语言编写的 kernel 映射到具体硬件的执行码上,还需要设计并开发相应的 Triton 编译器来完成映射。因此,当我们提到 Triton 时,实际上指的是 Triton 语言与 Triton 编译器的结合体 👉 Triton Language + Triton Compiler!所以我也计划分两次撰写相关的文章。我个人今后的工作会更加偏向于关注 Compiler 侧。
Triton 的原论文标题即为:“Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations”,从中也可以看出这一点。
With CUDA being so powerful, why do we need Triton? 🤔 事实上答案也比较显然,Triton 最重要的目标之一是降低成本。在深度学习领域,常见的做法是直接在 Pytorch 或 TensorFlow 中进行开发。然而,当面对大规模实验(如 OpenAI 的 GPT-3 或 GPT-4)时,GPU 训练甚至推理的费用非常高昂。据报道,OpenAI 至今在 GPU 费用上花费了近 5 亿美元,而 Facebook 的 LLaMA 模型训练费用约为几百万美元。即使能减少 1% 的成本,对于这些企业而言,节省的费用也是巨大的。
要降低成本,一种解决方案是书写 low-level 的 CUDA 代码,而不是依赖 Pytorch 进行复杂操作管理。这确实能带来性能提升,但开发过程会变得非常繁琐,而且写出高性能的 CUDA 代码并没有那么容易。因此,OpenAI 推出了 Triton 语言,旨在提供比 CUDA 更高层次的优化,同时保持比 Pytorch 更接近底层的控制,以在性能和易用性之间找到平衡。
天然支持分块函数

上面这张图来自 Triton 官网,它告诉我们 Triton 的设计核心是基于“分块”操作。这里的“块”指的是一个 GPU 编程中的概念:线程块(Thread Block)。详情请参考 CUDA C++ Programming Guide。
不过 thread、thread block 和 下面要提到的 grid 本质上都是 程序员的视角。要完全理解 thread block,关键是要从硬件的角度了解它。硬件将执行相同指令的 thread 分组到 warp 中,几个 warp 构成一个 thread block。几个 thread block 被分配给一个流式多处理器(SM)。几个 SM 组成整个 GPU 单元(执行整个 Kernel Grid)。
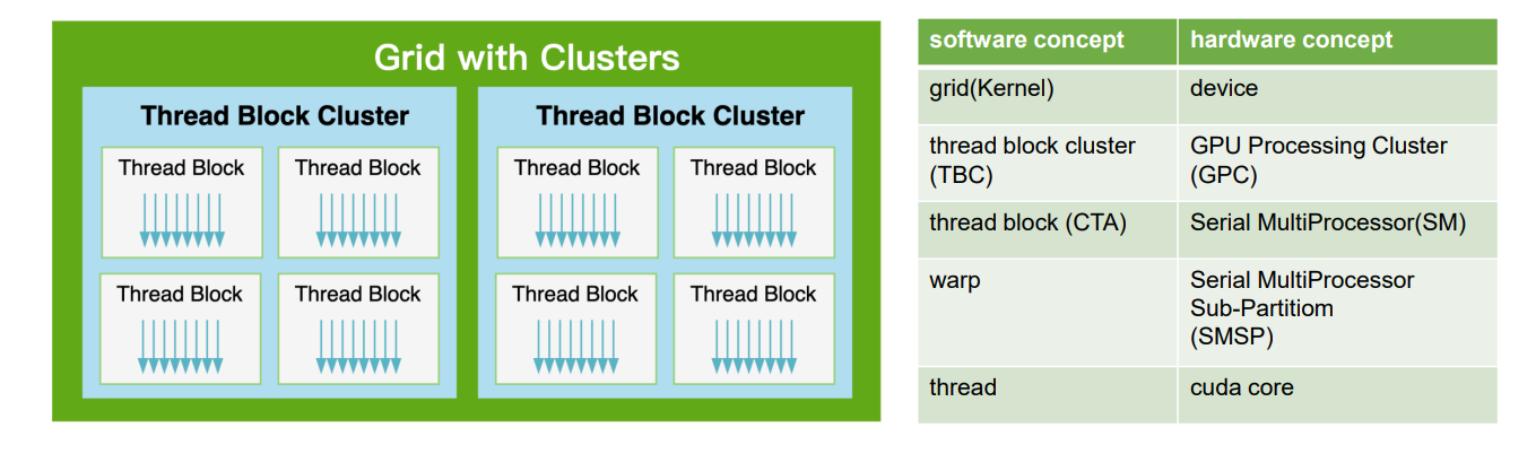
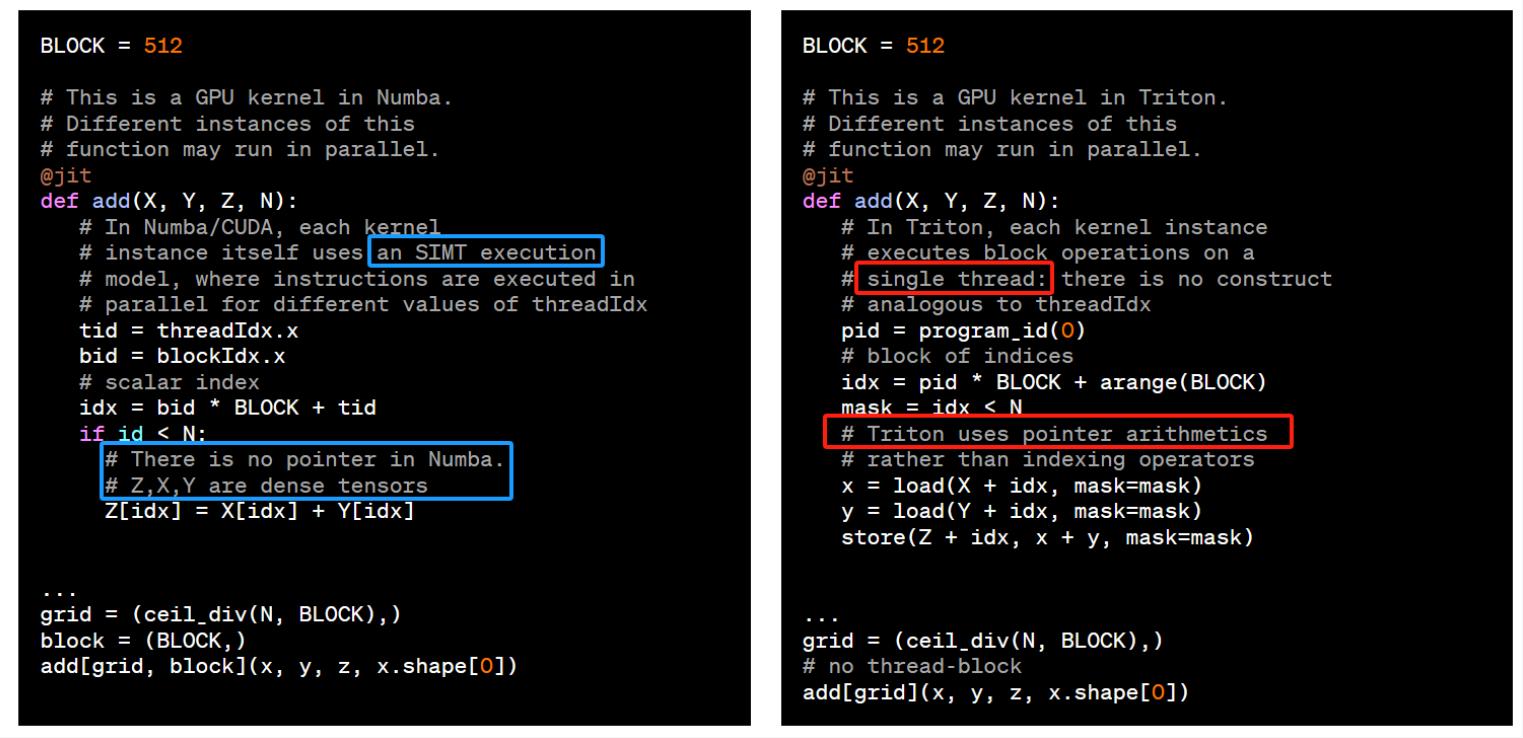
CUDA 编程是 Thread 级别的编程,即 SIMT Programming Model。每个 __global__ 函数仅描述了单个 thread 的计算逻辑。尽管实际的执行单元是 warp, 甚至有些 instruction 是 warp 级别的它们都需要表示为每个 thread 的计算。
相比之下,Triton 编程是 CTA 级别编程,即 SPMD Programming Model。在 Triton 里一个 kernel 函数描述的是一个 CTA 的运算。各个 CTA 之间的差别在于 program_id(见下节),并没有细化到每个 wrap 或者 thread 具体做什么,什么时候同步,什么时候使用 shared memory,等等。CTA 以下的细节和优化都由 Triton 编译器处理了。开发者主要关心 算法以及 CTA 级别的任务划分。
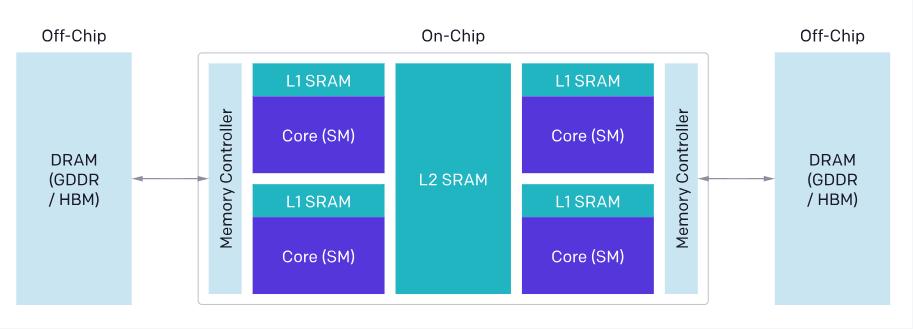
🌬 题外话:在讨论 GPU 编程时,我们必须先对 GPU 的架构有所了解。在 SM 以上,我们的视野大致如下所示:
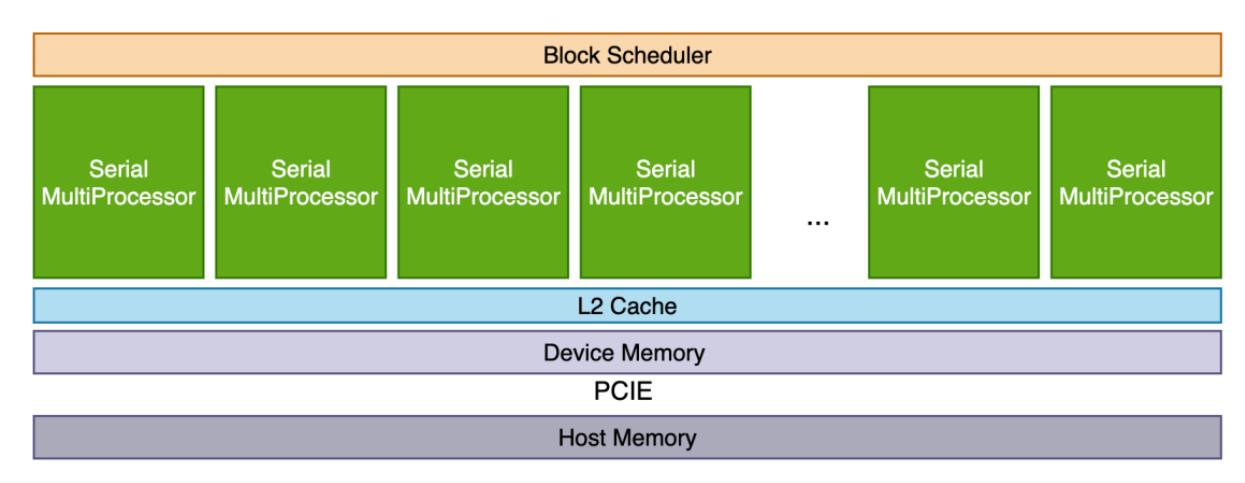
在这个 level,我们主要关心的内容从上至下大概是:
- In Block Scheduler:并发 Kernel 的调度问题
- In SMs:Thread Block 层的任务划分,也就是讨论更高效的分块机制
- In L2 Cache:缓存命中率,需要我们重点关注访存局部性的问题
因此在讨论 Triton 程序的优化时,可以重点关注这些问题。
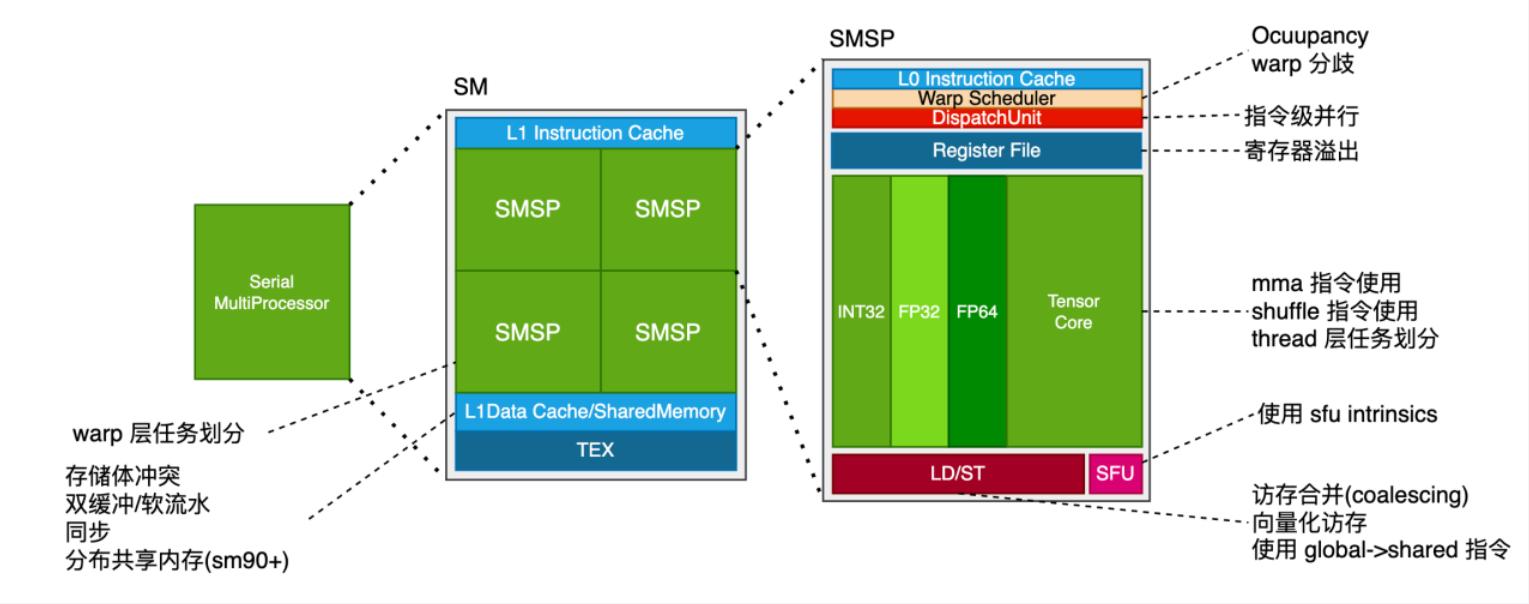
而在 SM 以下,需要做的事情可以更加细致,这些在更加 low-level 的 CUDA 编程乃至于汇编编程中都可以涉及:
Triton 如何实现任务划分
See in CUDA C++ Programming Guide,在 GPU 架构中,kernel 程序的执行是通过将任务划分为多个 block 来实现的,Triton 也利用了这个特性设计编程机制。一个 Triton kernel 会启动若干个程序(program),用于将工作分配到数据块上。我们可以根据硬件和算法的复杂度来控制要启动的程序数量,这一过程被称为 launch grid。
在 triton kernel 中,每个程序都会被赋予一个程序标识符(PID),通过 triton.language.program_id() 可以获取该标识符。
例如,假设我们有一个 6×4 的矩阵 A,需要计算每一行的和。一个简单的 kernel 分块机制可以为每一行启动一个程序,并让每个程序分别执行向量求和。启动网格可以表示为 (6, ),表示启动 6 个程序,每个程序处理矩阵的一行,如下图所示。
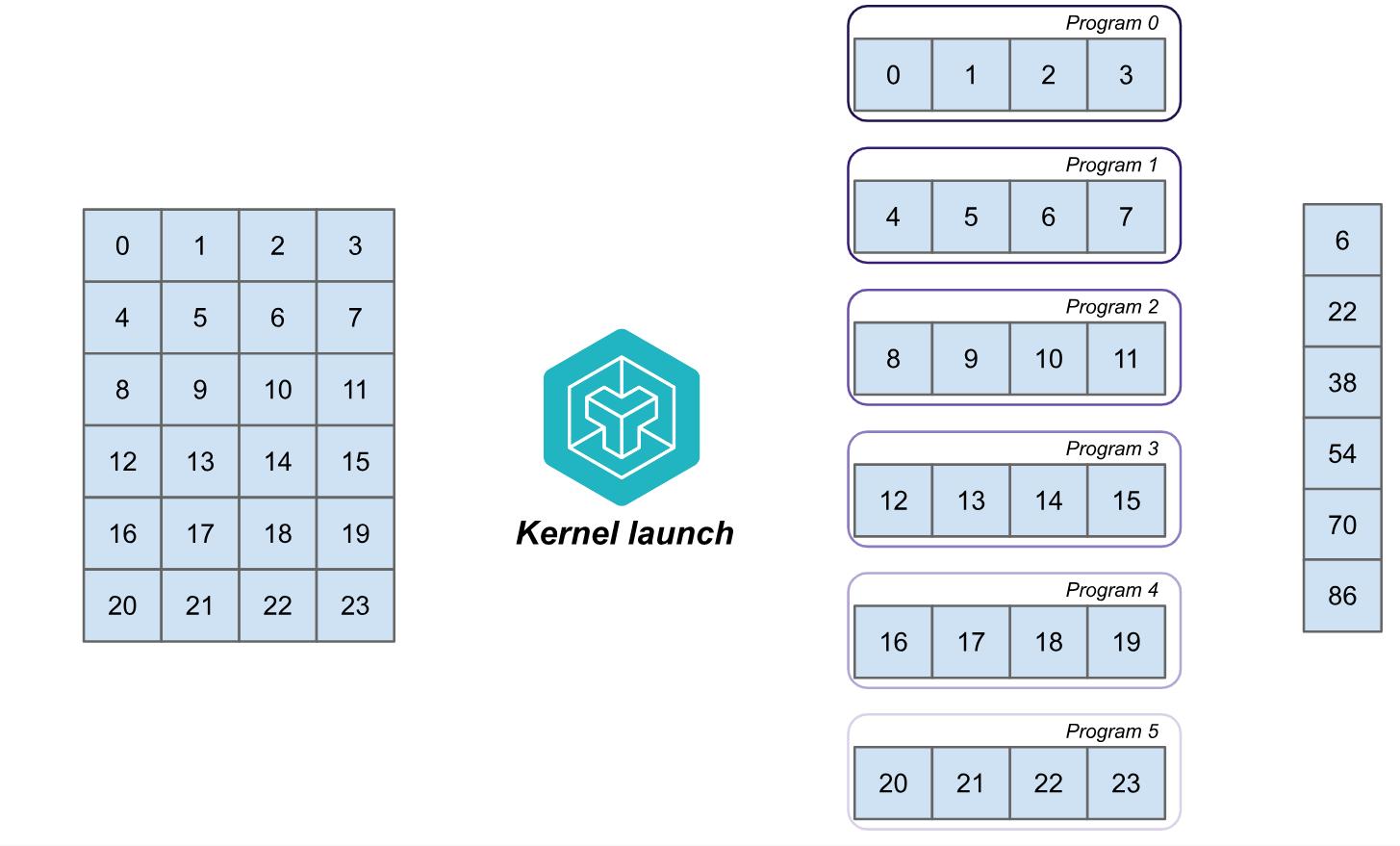
在左侧的矩阵 A 中,Triton 启动了 6 个程序,每个程序加载一行数据并将其和存储到输出向量中。可以通过如下代码设置 launch grid:
1 | import torch |
我们也可以将工作划分为行和列的集合。如果保持程序数量为 6,每个程序可以处理两行的一半。这时,启动网格将变为二维 (2, 3),如下图所示:
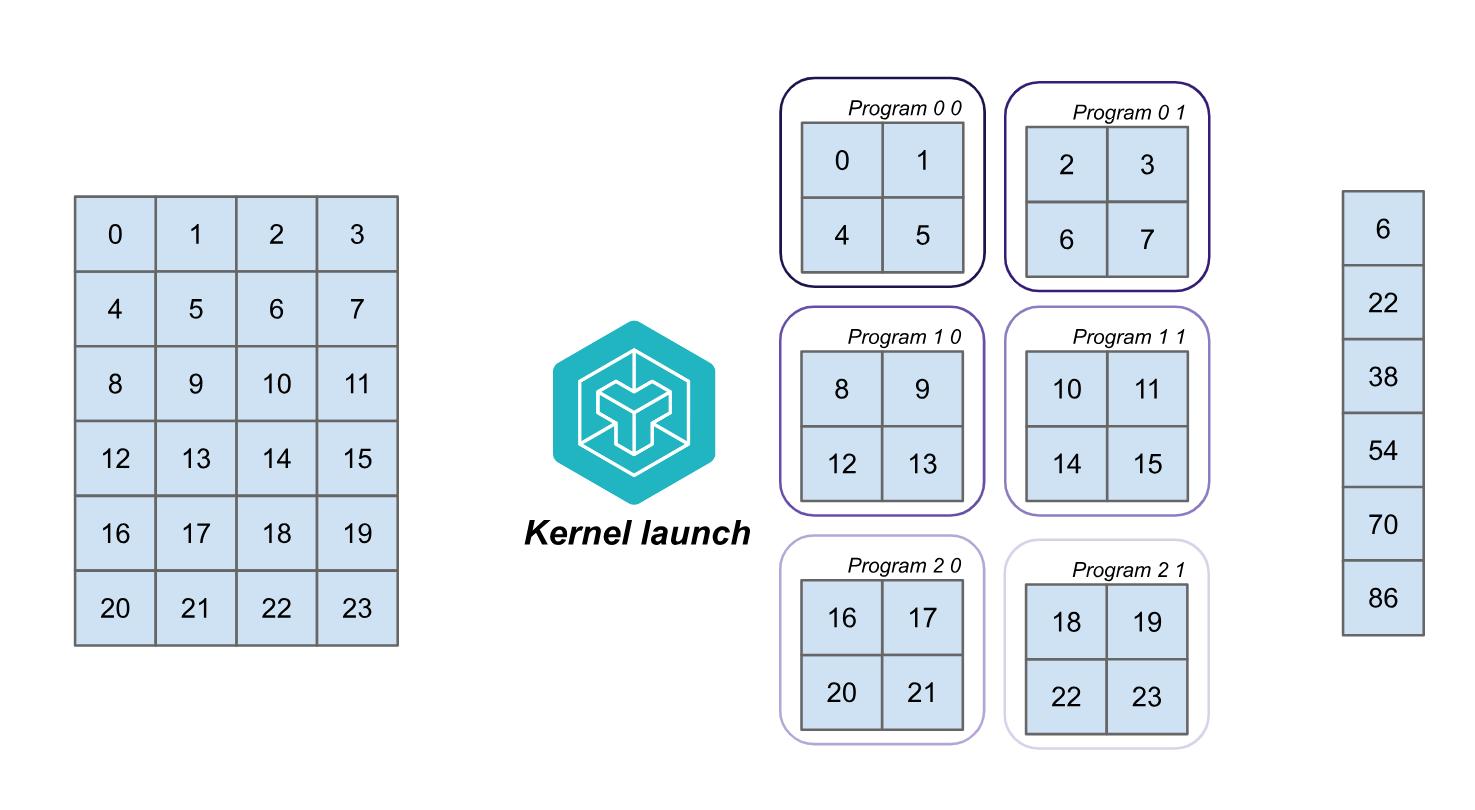
对应的分块代码为:
1 | import torch |
这种情况下,程序具有 x 和 y 轴的标识符,分别通过 pid_x = triton.language.program_id(axis=0) 和 pid_y = triton.language.program_id(axis=1) 获取(进一步地,你当然可以分配 3d grid,再增加一个 batch 维度)。不过使用 2d grid 可能会影响性能,因为我们此时不再是加载连续的内存块,显然这有可能影响 L2 Locality。比如,看下面这个矩阵乘法的例子:
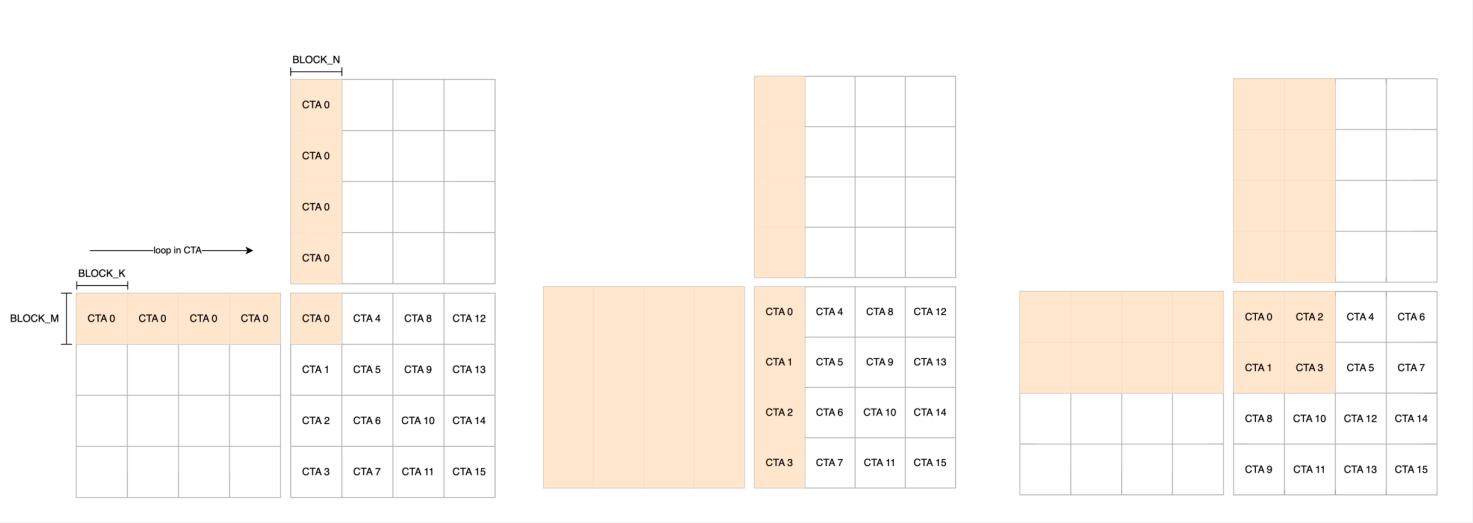
显然,相比 p1 的读 4+4 写 1 和 p2 的读 16+4 写 4,p3 的读 8+8 写 4 可以更有效地提升 L2 cache 命中率。这里我们要注意,Triton 中 CTA 的编号和启动顺序是 有关 的。
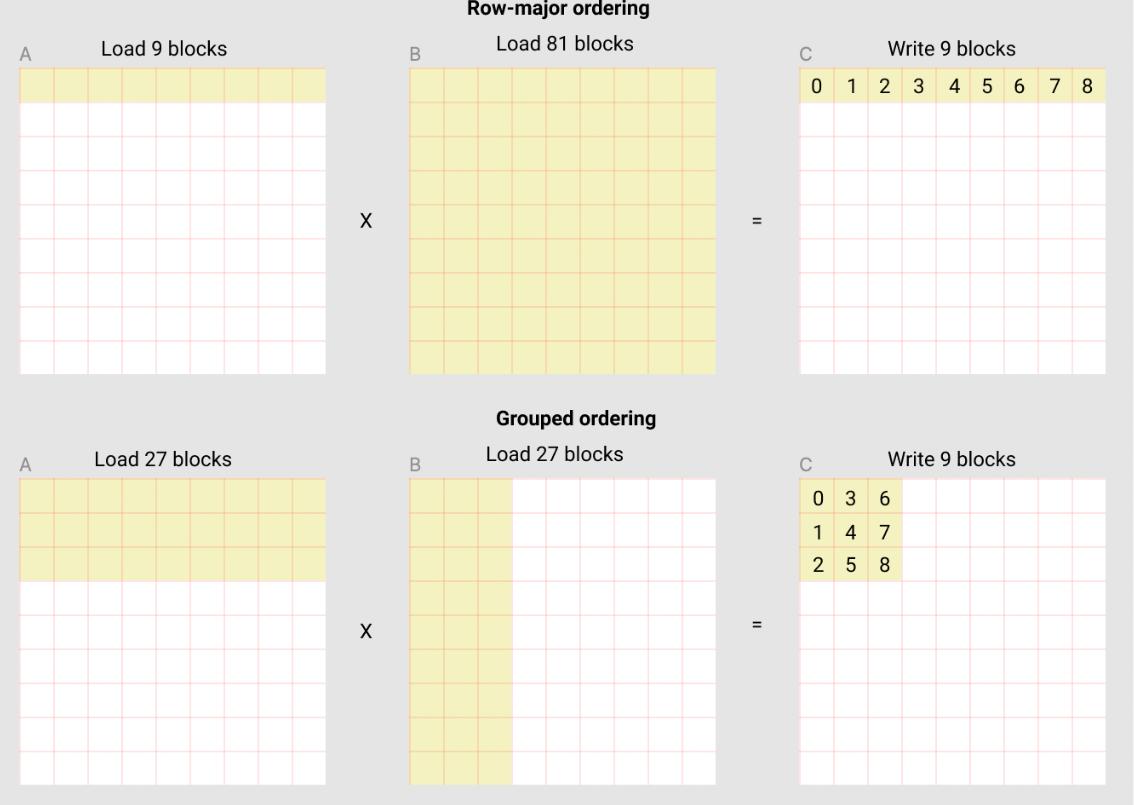
一个更直观的 L2 Cache Optimization 例子来自 Triton 官方:For example, in the following matmul where each matrix is 9 blocks by 9 blocks, we can see that if we compute the output in row-major ordering, we need to load 90 blocks into SRAM to compute the first 9 output blocks, but if we do it in grouped ordering, we only need to load 54 blocks.
或许你已经注意到,pid 不仅仅是用来指示 CTA 的编号的,我们还需要利用它计算正确的偏移量,以在程序内部读取到正确位置的数据块。不过 CUDA 中也有类似的概念,所以此处也不必再展开细说。
在简单情况下,我们可以设置 offset = A_ptr + N * program_id,这里的 N 是矩阵每行的元素数,A_ptr 是矩阵 A 的指针。如果矩阵 A 的 stride 是规则的,这种方法是有效的。然而,在实际应用中,我们不能总是保证 stride 是规则的,在处理具有不规则 stride 的矩阵时,需要把你需要的维度的 stride 作为参数传入 kernel 参与运算。
值得注意的是,截至此文撰写时,triton 仍不支持 list 作为 kernel 函数的参数传入,所以请不要指望可以传一个完整的 strides 数组。
这里,如果你希望读入一个 block 里所有元素的 offset 构成的一组指针,可以使用 triton.language.arange() API。例如,offsets = A_ptr + N * program_id + triton.language.arange(0, BLOCK_SIZE)。
从这个写法里,你可能还注意到了我们总是通过指针访问向量。这一点在 triton.language 文档有关访存的 API 里也有体现。

这是因为 Triton 的 JIT 编译器始终将向量处理为指针,它认为保持对内存访问的 low-level 控制对于处理更复杂的数据结构(如 block-sparse tensors)至关重要。通过准备 block 指针,我们可以开始将数据从 global memory 加载到速度更快的 shared memeory 中。如下图所示,这跟 CUDA 程序是存在差别的。
Triton 如何动态变更分块规模
在 Triton 中,launch grid 不一定需要直接写死成一个整数元组,它是一个 callable object,分块模式可以动态变更。动态的好处在于可以帮助后续调优(See in triton.autotuning),选择性能最佳的分块参数。例如:
1 | def sum_row_blocked(A: torch.Tensor) -> torch.Tensor: |
这段代码通过指定 BLOCK_M,使得分块可以随着 BLOCK_M 的变化动态调整。
掩藏底层硬件的优化细节
Triton 的另一个重要设计理念是掩藏更多的底层硬件优化细节,让程序员不需要像书写&优化 CUDA 时那样考虑太多 GPU 架构相关的特性,而是由 Triton 编译器自动完成这些工作。我们知道现代 GPU 的架构主要包括三个重要组件:DRAM、SRAM 和 ALU。在优化 CUDA 代码时,也经常需要充分考虑这些组件的特性:
- DRAM 内存传输:内存传输必须进行合并(coalesced),以利用现代内存接口的大总线宽度。这有助于提高内存带宽的利用率。
- SRAM 数据重用:在重用数据之前,必须手动将数据存储到 SRAM 中,并对其进行内存组织管理(如数据重排),以减少共享内存中的 bank conflict。
- 流式多处理器(SM)调度:在流式多处理器之间以及内部,必须仔细划分和调度计算任务,以提高指令/线程级别的并行性,并充分利用专用的 ALU(如张量核心 tensor core)。
- ……
优化这些底层硬件细节对经验丰富的 CUDA 程序员来说也是一项挑战。
Triton 的主要目标就是完全 自动化 这些硬件优化过程,使开发人员可以更专注于并行代码的高级逻辑。不过 Triton 不会自动安排跨 SM 的工作,一些 SM 级以上的重要的算法考虑因素(如 tiling 和跨 SM 调度中的同步)依旧会留给开发人员自行决定。这一点在前面也已经有所提及了。
CUDA 与 Triton 中的编译器优化大致有以下异同:
| CUDA | TRITON | |
|---|---|---|
| Memory Coalescing | Manual 手动 | Automatic 自动 |
| Shared Memory Management | Manual 手动 | Automatic 自动 |
| Scheduling (Within SMs) | Manual 手动 | Automatic 自动 |
| Scheduling (Across SMs) | Manual 手动 | Manual 手动 |
Triton Language(API)
这一部分很无趣,通过查看官方文档基本可以解决所有问题,没什么好说的,简单挑一部分说说。
triton.jit decorator
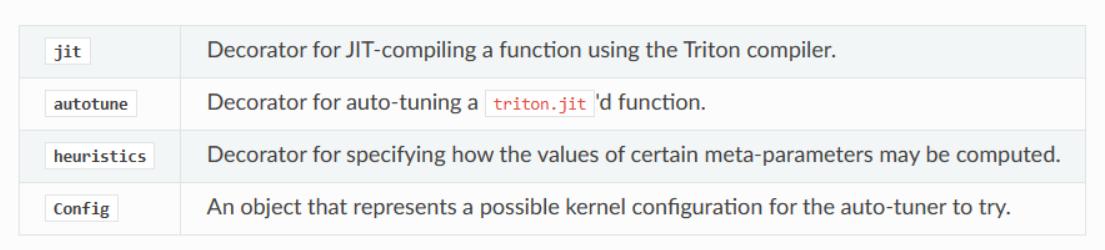
需要注意的是 triton.jit,写函数之前需要加上这个 decorator,这使得这个函数将会被继续解析成 Python 的 AST, 也就是 Python 的抽象语法树,会继续往下 lower,最后将在 GPU 上编译并运行。A function that has the decorator can make use of the triton domain specific language inside of it,然而,它只能访问:
- python 基本函数
- triton 包内的内建函数
- 这个函数的参数
- 其他经过 jit 编译的函数
而且,这样处理后的函数的参数都会被处理成 指针,且函数必须有参数。
load & store
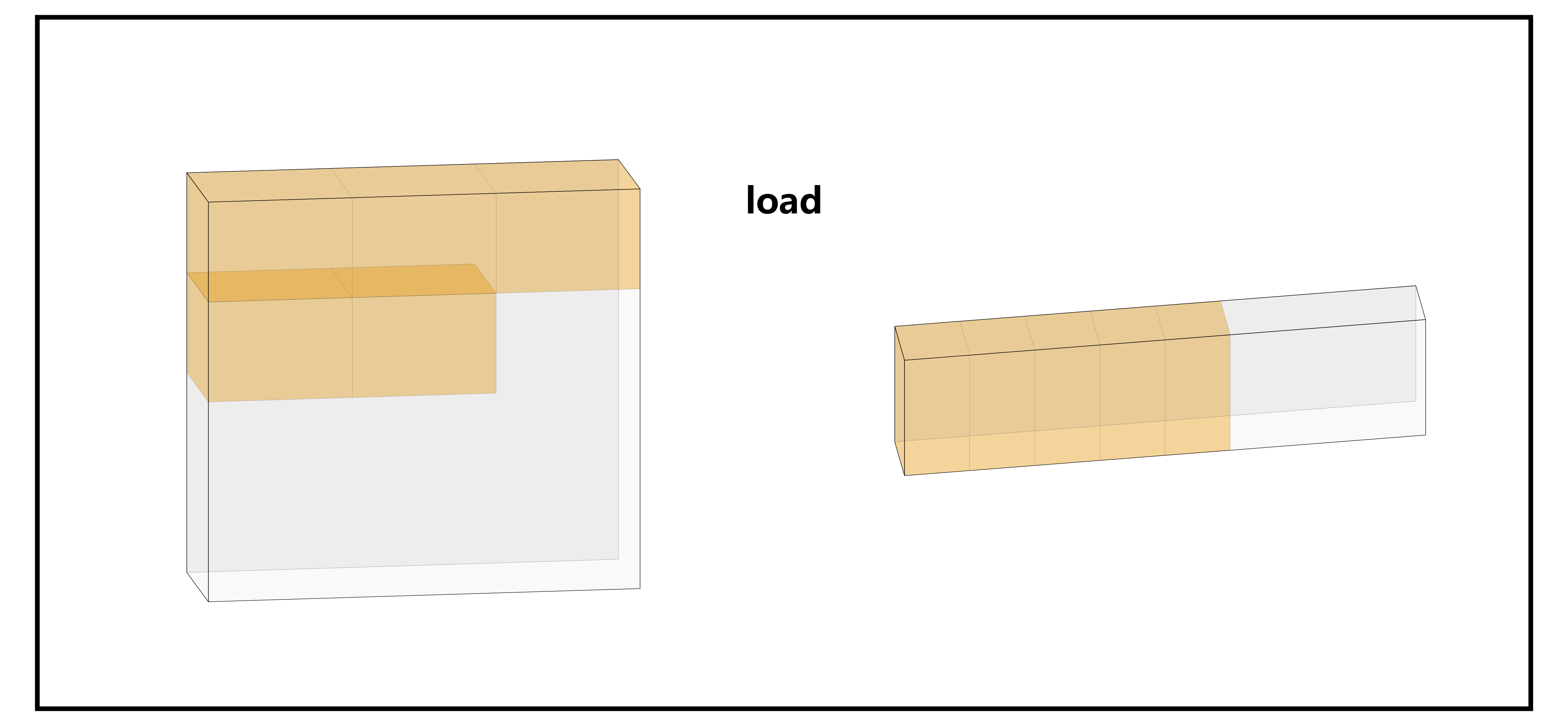
与之相关的是 Memory 相关的 API:tl.load 和 tl.store。这里想说明的是前面已经谈及过的 offsets 指针定义和 mask 参数。
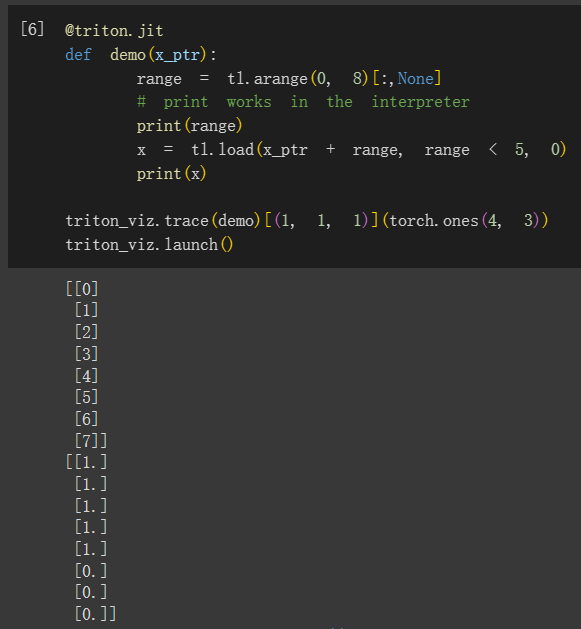
mask 参数很重要。从字面意义就可以看出,它可以用一个布尔遮罩帮助我们做很多防止越界读写的操作。即使是最 naive 的数据读写也需要关注 mask,因为 Triton 规定过所有的 shape 必须是 power-of-2,也即我们读入的指针数组的 range 必须满足这个要求,但实际上输入数据很有可能填不满,这个时候就要用 mask 控制一下。一般来说,会写 mask = offset < n_elements,填不满的部分被 0 补上(当然,你也可以指定成其他的越界值,比如 -inf)。下面是一个 tl.load 的样例:

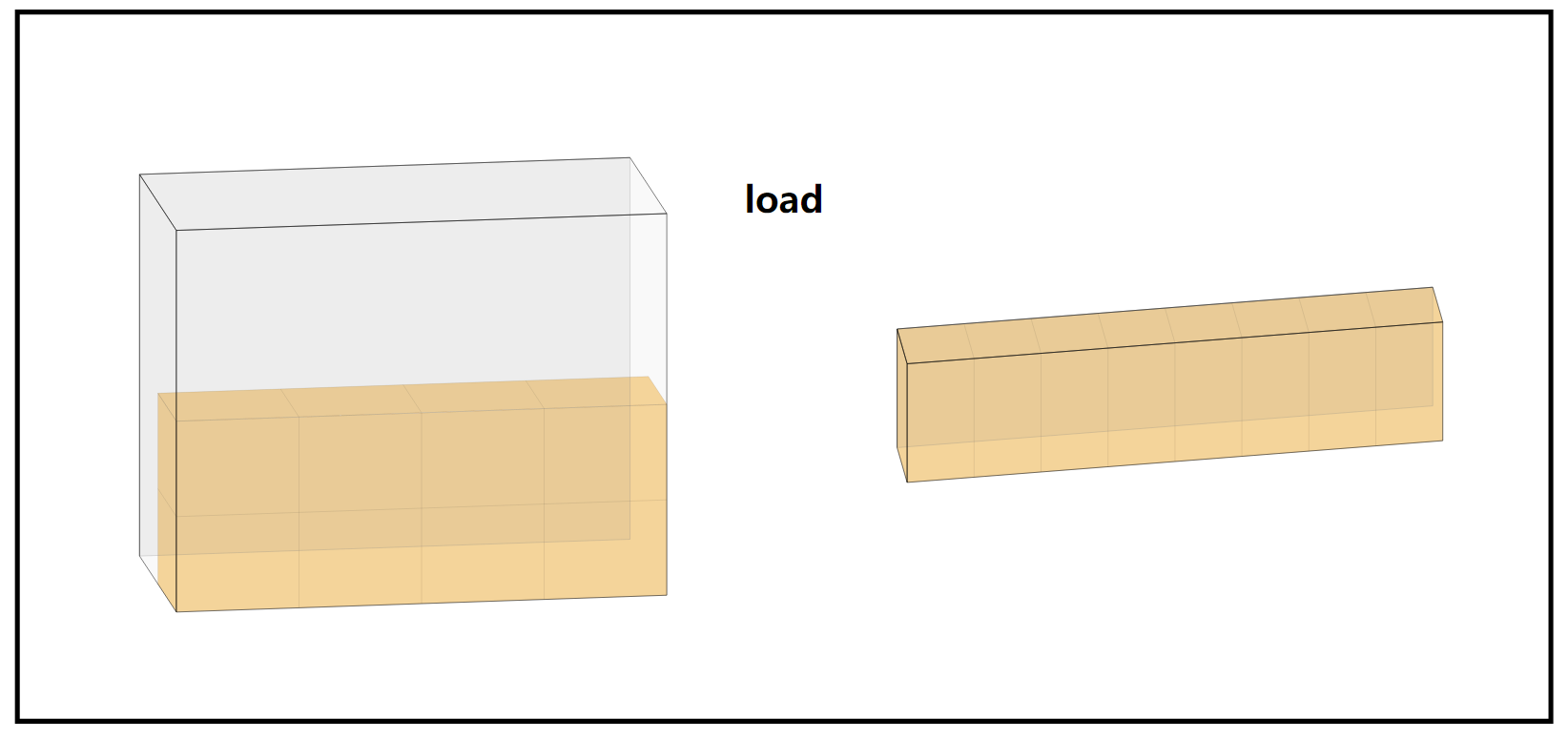
下图是用 triton-viz 实现的上述代码可视化结果。左侧是内存中的情形,也就是输入;右侧是一个 BLOCK 内读取的 offsets(也就是示例代码中的 range)的情形。黄色高亮是 mask 覆盖的元素的情形,也即真实从内存中 “读取” 的数据。
假如我们想要在 kernel 里读写 2D Array,或者更高维度,可以利用 None 关键字。用法跟 Pytorch 里是一样的。

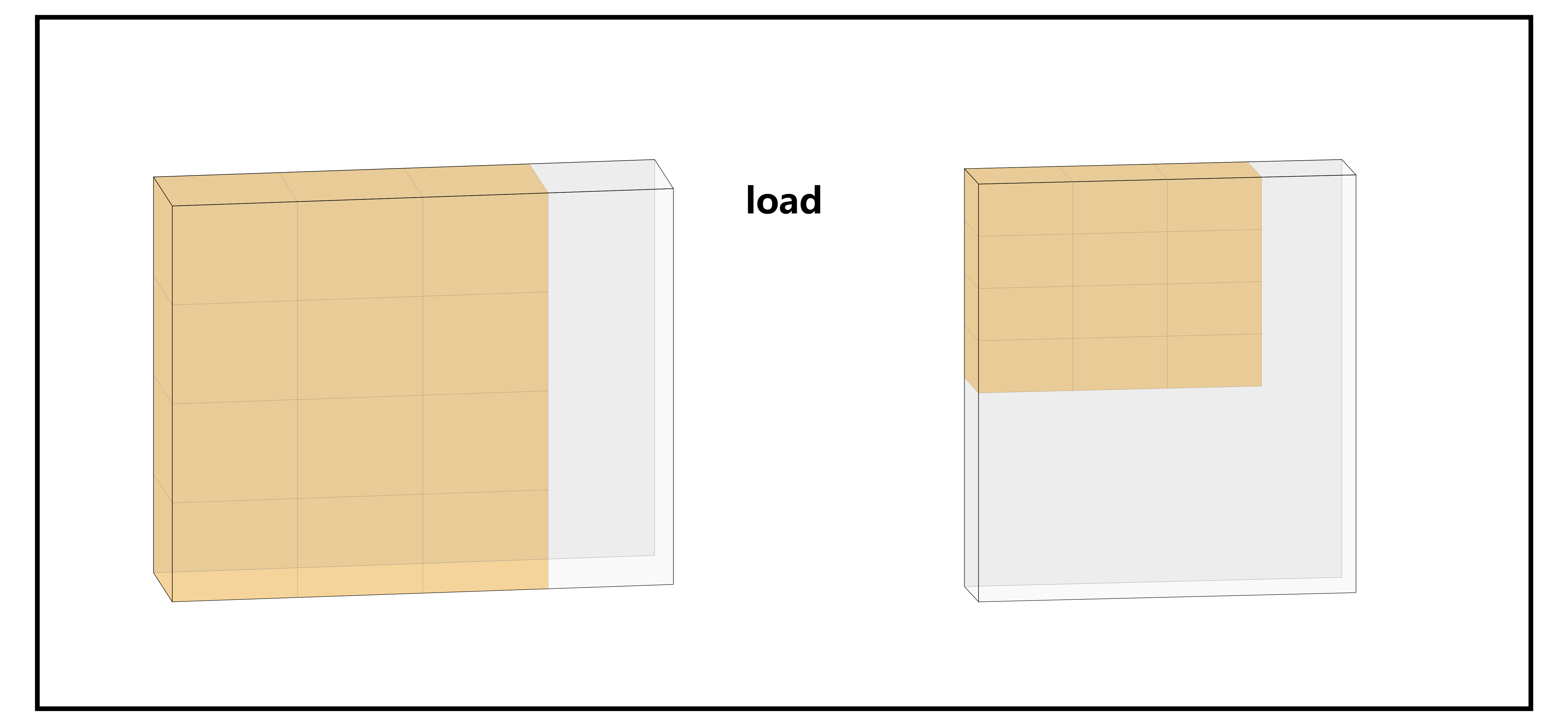
具体到每一个维度上的 offsets 时是这样的:
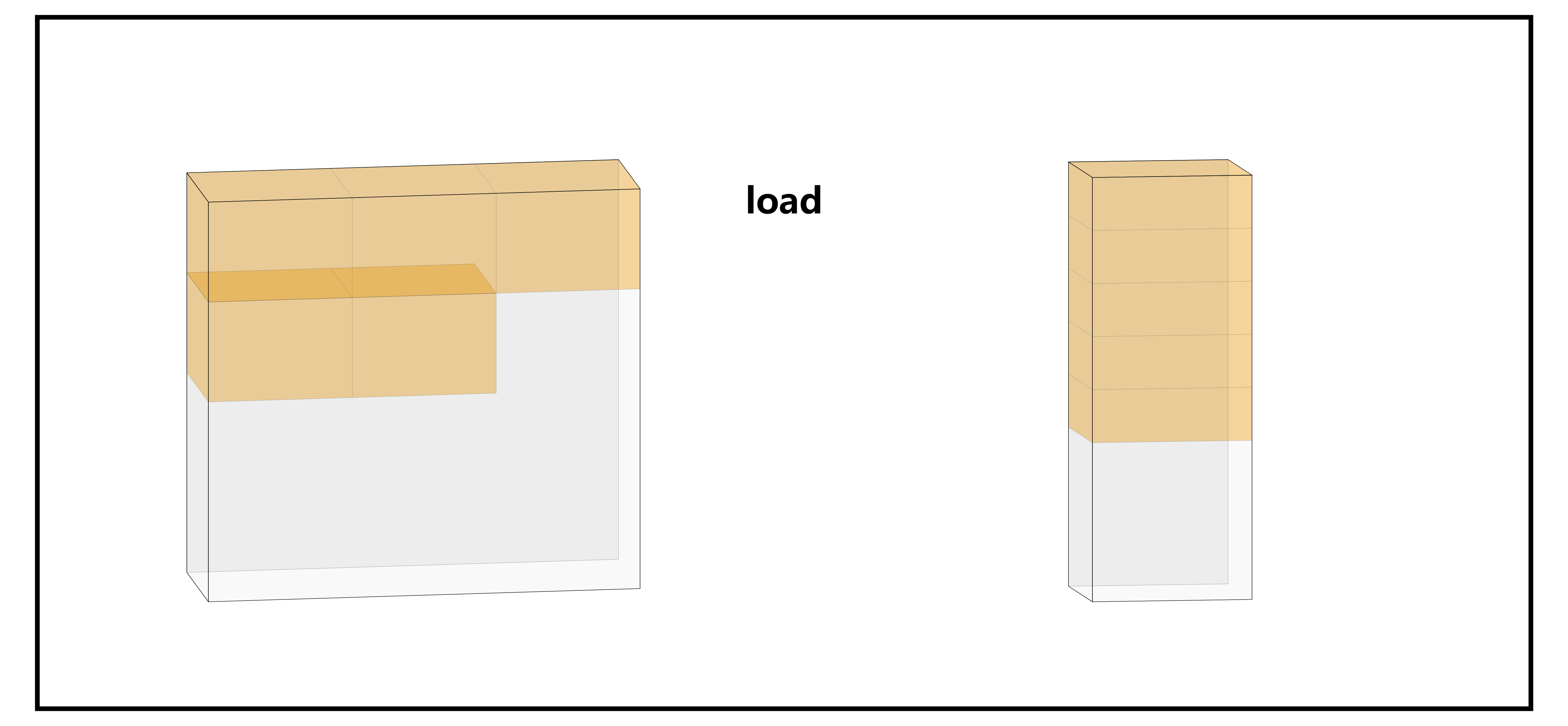
我们还可以通过下面这个样例体会一下不同的 2D array 创建方法对元素访问 / 存储的顺序造成的影响:
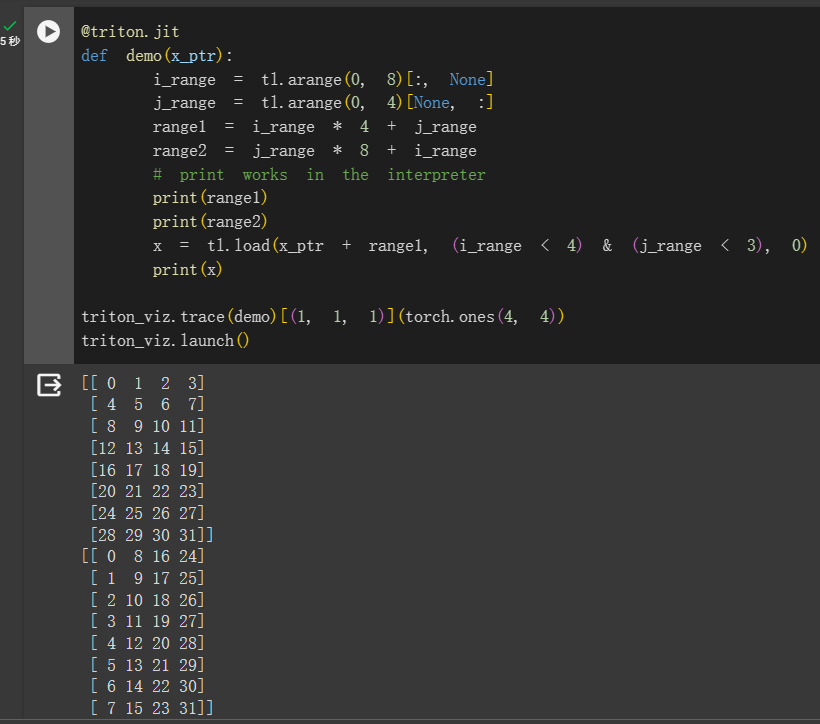
当然,我们也可以用 tl.make_block_ptr 这个 API 去做加载多维 array 这个事。但这个 API 有许多不便之处,此处暂时不展开,平时开发中我个人是会尽量避免使用它的。
store 的表现与 load 是类似的:

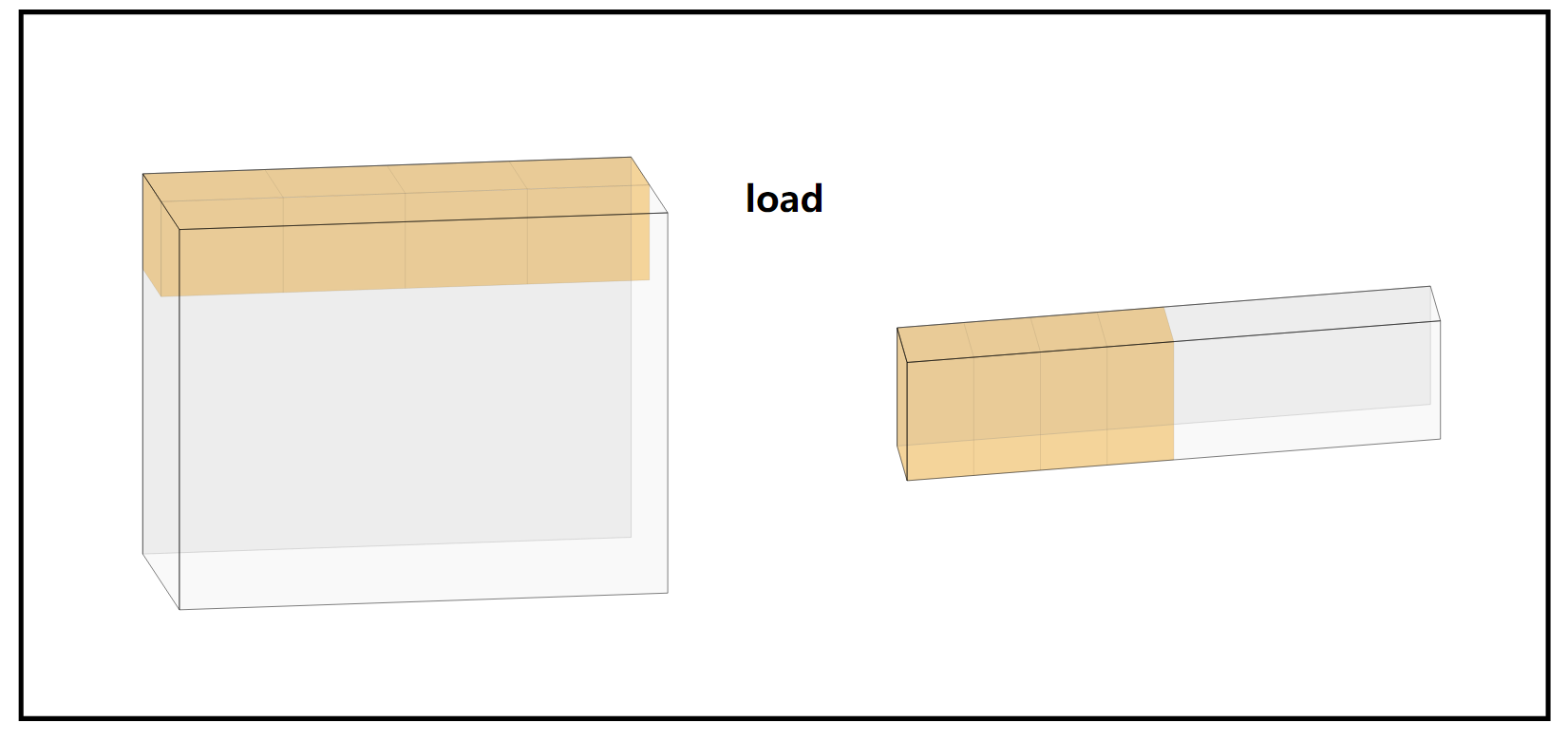
这个图例与上面的方向相反,左侧是 BLOCK 内情形,右侧是内存内的情形。
加上 pid 对 offset 进行指定之后,就可以控制不同块的并行行为了:
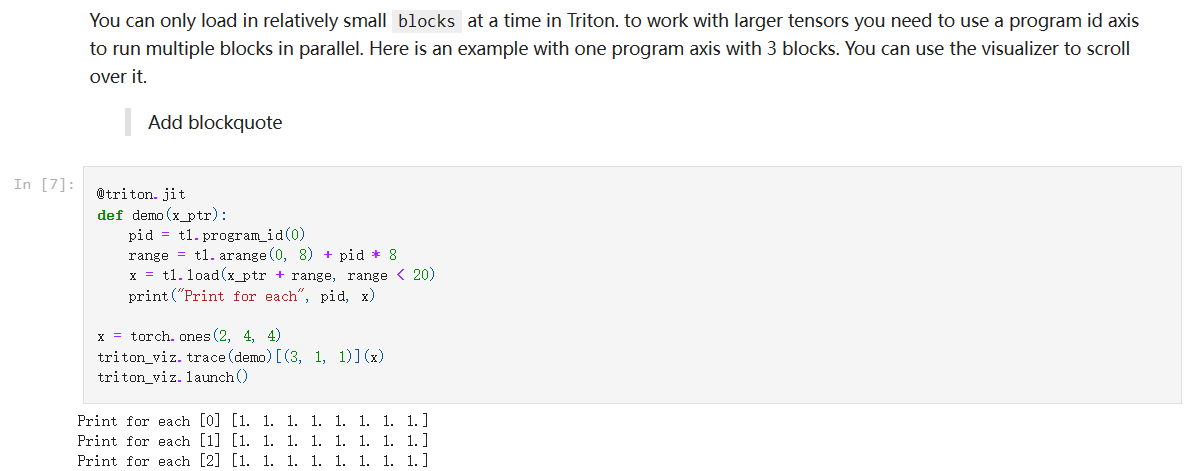
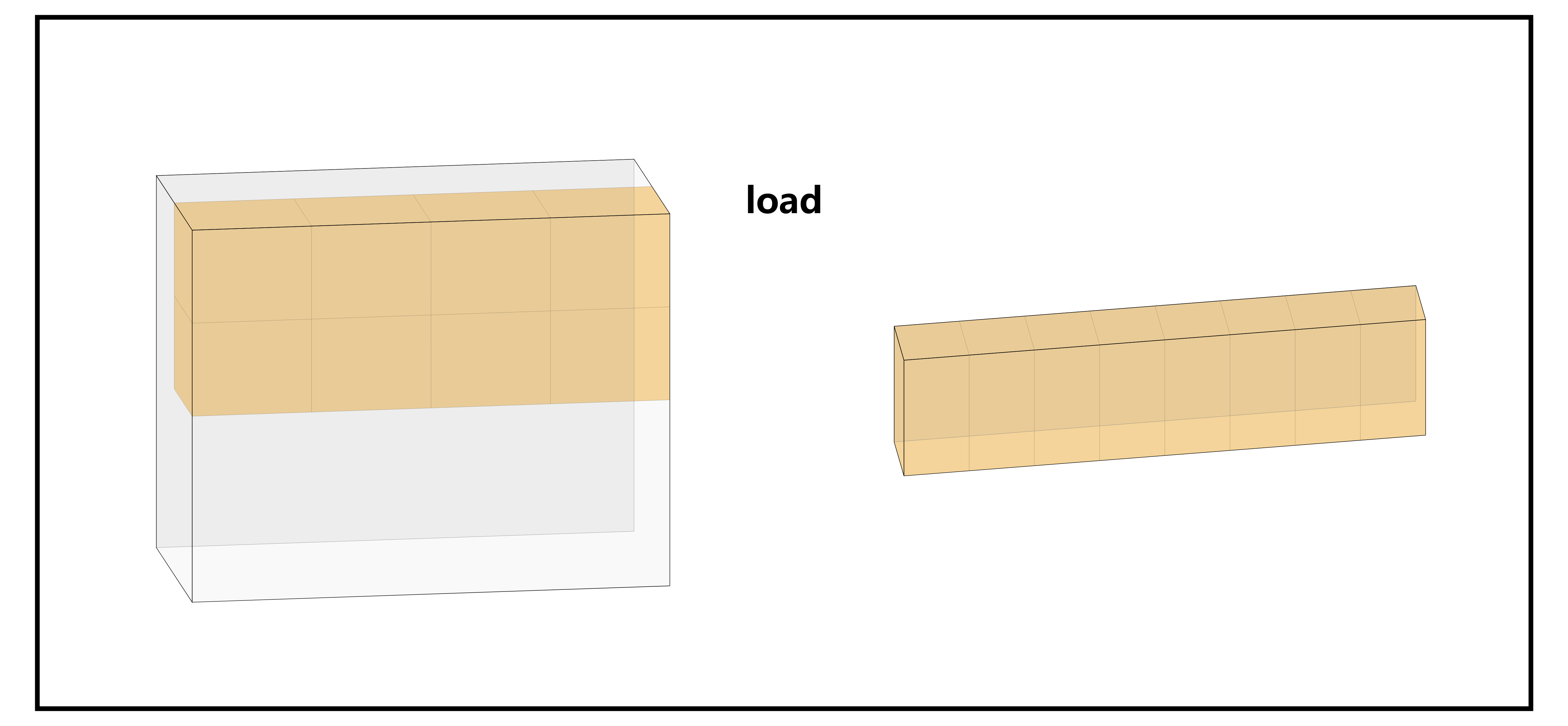
pid = 2 时,由于 mask 的控制,只能读进来 4 个:
使用 2D 的 offsets,可以完成类似下图的 load-store 操作:

Triton JIT Compiler
Mainly from the paper(MAPL’ 19)
这里非常简单地说一说背后帮忙做底层硬件优化的 Triton Compiler,后面会另撰文章。Triton JIT compiler 用于将 MLIR 转换为目标机器代码,由一些机器相关和机器无关的 pass 构成。
机器无关 Pass
-
Pre-fetching。compiler 的工作是检测循环,然后为其添加必要的、充足的预取代码。
-
block 级的窥孔优化。主要是利用一些矩阵的代数性质做表达式替换,提供可能的优化时机。例如,。
机器相关 Pass
- Hierarchical Tiling,俗称的多级分块。一些有关多级优化的背景之前已经提过。
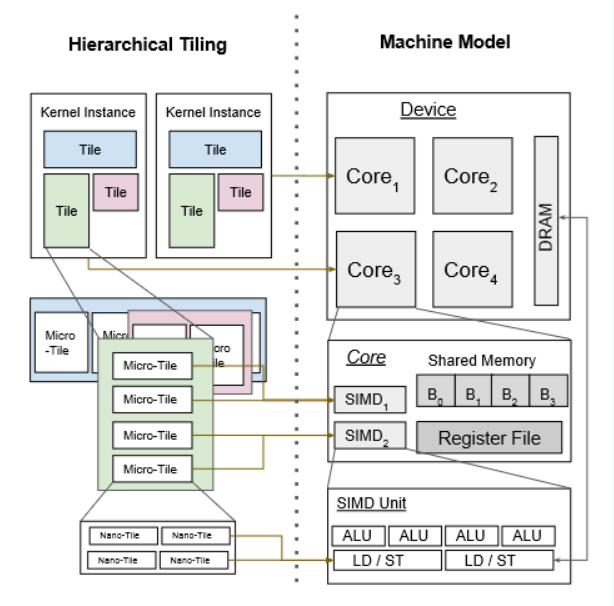
- Memory Coalescing,俗称的内存合并。优化动机很简单,就是当相邻线程同时访问附近的 memory locations 时应当对 memory 进行合并,有点类似 OS 里整理空闲块的操作,这样可以有效减少加载一个 block 列需要的内存访问次数(因为这可以尽量将需要访问的 locations 集中到一个内存块里,避免多次存取)。
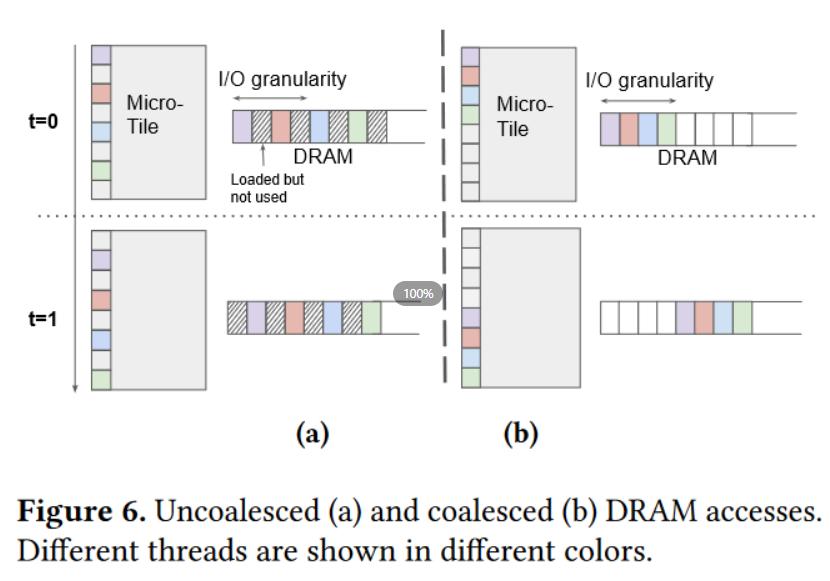
-
Shared Memory Allocation。Triton 的实现是一个实际上很经典的静态分析方法,先计算所关注变量的活跃范围,然后利用这些信息执行线性时间的存储分配算法(See in: Jordan Gergov. 1999. Algorithms for Compile-time Memory Optimization. In Proceedings of the Tenth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA ’99).)。
-
Shared Memory Synchronization。类似流水线中自动插入 nop 指令防止发生数据冒险的技术。
Auto-tuner
“autotune” 指的是一种自动调节模型超参数的方法,通常使用启发式算法或优化技术来搜索超参数的最佳组合,以优化模型的性能。
Triton 原论文的工作只讨论了多级分块这一个优化 pass 的 tuning,是通过级联 pass 的元参数来扩展优化空间的。
而在具体的编码应用中,我们可以用 triton.autotune 这个 decorator 选择合适的 BLOCK_SIZE,进一步优化动态调整 launch grid 的过程。See in Source code :
例如,我们可以把原始的:
1 | def add_kernel( |
改写成带 autotune 的:
1 |
|
然后 Triton JIT compiler 就会在运行中挑选 运行时最优 的那个 Config 作为最终的参数选择(哈哈,这哪里 auto 了)。
实际情况中还可以用下面这种方式稍微简写一下多个 Config:
1 |
|