
综述
TVM 是在把训练好的机器学习模型部署到不同设备上时使用的 深度学习编译器 。其实此处 “编译器” 的概念并不非常传统,只是 Inference 的过程与编译极其类似。具体而言,一个机器学习模型本身可能写自不同的框架,例如 TensorFlow、PyTorch 等,这意味着它们使用了不同类型的算子,而要部署到的目标硬件也可能采用不同的指令集架构(x86、ARM 等),因此我们需要一种方法让基于 Framework x 的 ML Model 能够在采用了架构 y 的硬件上运行(并且 高效 运行,否则没有意义) —— 这跟编译及其优化的过程是非常像的。所以,被用来完成此类功能的工具就被称为深度学习编译器。
人工智能技术的落地可以分为 Training 和 Inference 两步,前者用于在算法层面上产生一个 “模型” ,后者则指代将模型部署到目标设备上运行的过程。对 Training 来说,市场的主流框架基本已经确定,而 Inference 的情况则不尽然,因为不同公司和应用场景采用的硬件架构很有可能非常不同。
一开始的情形是各大硬件厂商基本都针对自家硬件推出自己的 Inference 框架。但不管是关注商业利益的业务方,还是关注学术价值的程序员,大家的目标并不是让 Model 在单一的硬件平台上表现得足够好,而是追求一个统一的 Inference 框架,让模型在多种设备中都能保持高效的执行性能 —— 这就将思路引到了传统编译优化的层次抽象上,TVM 就是一种基于编译优化思想的推理框架。
深度学习编译器借鉴了 LLVM 的设计思想:将部署的过程抽象成前端、中端和后端,重点是在中端引入了不同平台 共享 的 IR 。在深度学习问题中,是将计算图(也有称为模型流图的)作为 IR ,称为 Graph IR ,然后对图 IR 做一系列标准的流图优化操作,例如循环调度、算子融合等,TVM 提供了前端框架 NNVM ,使得来自各种框架的模型可以转换为图 IR 。作为深度学习编译器的一种,TVM 主要解决 后端 的问题,即接收优化后的图 IR 作为输入,然后自动生成针对特定硬件平台的代码,目标是在不同硬件上高效地运行 IR 。跟传统编译器不同的一点是,实际场景中 TVM 的输出往往是 CUDA 源码这类的 算子代码 ,完成的本质上是计算优化的工作(这个优化以往通过手工进行编写),真正编译到机器码的工作还是交给设备提供商,被称为 “下游编译器” 。当然,这些自动生成的算子也可以结合手工做进一步优化。
算法顶层也为深度学习加速做了很多工作,例如 [4] :更好的分布式训练调度(大规模分布式机器学习系统),更好的优化算法,更简单高效的神经网络结构,更自动化的网络搜索机制(神经网络架构搜索 NAS ), 更有效的网络参数量化剪枝算法、卷积运算的优化等等。
关注后端决定了 TVM 是跟具体硬件深度集成的,这表明,TVM 需要针对不同的硬件平台实现相关的 AI 算子。初始时使用人工调优算子,这无疑是非常麻烦的,后来在算子调优步骤引入了机器学习方法,诞生了 AutoTVM [1] 机制,使得 TVM 具有了非常强的适应性,表现在能够很好地适应各类业务模型,性能也大大提升 [2] 。
编译流程示例
TVM 官方文档 [3] 中用这张图概括了它的编译流程:

这张图表示的流程在很多地方被称为 TVM Stack 。前端将来自深度学习框架的模型导入,生成 IR 模块,针对这个 IR 模块可以做一系列优化(图中称为 Transform,类似我们了解的 IR 优化),例如 量化 等。然后编译器会将 IR 模块中的内容翻译成目标平台指定的可执行格式,翻译结果被封装成可以在目标运行时环境中导出、加载和执行的运行时模块,具体而言是 tvm.runtime.Module 这个数据结构,通过 TVM 提供的一系列方法(GetFunction 等)可以从模块中取到编译优化的模型结果,在目标平台上执行调用。可以看到,执行优化的时候还采用了 AutoTVM 机制,对生成的算子进行调优,具体而言,是对优化趟的执行顺序做调优。
量化是一种深度学习加速优化方法,指统计网络权重和激活值(一般是 FP32 型浮点数)的取值范围,找到其最大值和最小值后进行 min-max 映射,把所有的权重和激活映射到其他范围中,一般是 INT8 整型范围。显然,这是一个从体系结构角度出发的优化思路,用于减少运算的访存开销和乘法器数量。
就像前面说到的那样,TVM 不负责将模型编译到底,编译到机器码的工作交给下游编译器去实现,它的 “目标代码” 可以是 CUDA C 这样硬件导向的算子代码,也可以是传统的 LLVM IR ,如下图所示(来自知乎用户 手把手带你遨游TVM )。
TVM 在运行时模块这个数据结构中还提供了很多从编译结果到高级语言(例如 Python 和 C++ )的 API ,通过调用这些 API ,用户就可以像调用 numpy 一样调用它的编译优化机制,在各种平台上书写、部署更加高效的模型。
写到这里,感觉 TVM 完成的本质上是一个 到算子层面 的统一过程,来自不同框架、采用了不同算子的模型经过它的编译优化处理之后,变成一系列高性能的、基于某些高级语言(或者某些特殊的硬件导向的语言,例如 CUDA 、OpenCL 等)的函数结果,然后用户使用对应的语言,在不同的硬件平台上调用编译结果、编写代码。该硬件设备提供商自己提供的高级语言编译器则完成从高级语言到机器代码这一步。举个不太恰当的例子,有一个需要将模型部署到手机芯片中运行的场景(例如⚪图秀秀),手机芯片中运行的代码就是一些 import 了 tvm 库的高级语言程序,它的内容就是加载编译得到的可执行结果,然后按需运行模型。例如下面这段代码:
1 | import tvm |
Relay Passes 和 TIR Passes
讨论左列的两个黄色块。
不同于传统的编译中端,此处的 IR 模块是由一系列 TVM 定义的函数而不是中间表示代码组成的。这些函数包括两种主要的变体: relay::Function 和 tir:PrimFunc 。前者是一种高级的函数式程序表示,通俗地说是一系列 lambda 表达式,是图部分的 IR ,文档建议将其视为一个计算图,支持控制流、递归和复杂的数据结构,针对它进行的编译优化 Pass 称为 Relay Pass ;后者则是一种底层的程序表示,是算子部分的 IR ,包含循环嵌套选择、多维 load/store 、线程、向量/张量指令等元素,其实也就是我们平时说的算子代码了,针对它进行的编译优化 Pass 称为 TIR Passes 。
在 Relay Passes 中完成的有常见的编译优化,例如常数折叠和死代码删除,也有一些针对张量计算设计的优化,例如布局转换(Layout Transformation)和比例因子折叠(Scaling Factor Folding)。
- 布局转换(Layout Transformation):通过调整数据的存储方式和排列顺序,以提高数据的访问效率和内存局部性。在深度学习中,常见的布局转换技术包括通道重排(Channel Reordering)、融合多个卷积层的操作等。布局转换技术可以减少数据在存储器中的碎片化,提高数据访问的连续性,从而加速模型的计算过程
- 比例因子折叠(Scaling Factor Folding):用于减少乘法操作中的浮点数乘法运算次数。在神经网络的计算过程中,乘法操作通常涉及一个浮点数乘以一个常量比例因子(如权重或缩放因子)。比例因子折叠的目标是将多个乘法操作合并为一个乘法操作,以减少计算量。这种优化技术可以通过重新组织网络层或权重的方式来实现,从而降低模型的计算开销
在 TIR Passes 中完成的优化则大部分针对 “Lowering” 这个目标,基本是一些底层优化,例如将多维的访问扁平化为一维指针访问,展开一些内部函数,简化访问索引等等。毕竟这个步骤是为了完成算子代码的性能优化。还有很多底层优化可以在目标代码生成阶段由 LLVM 、 CUDA C 和其他目标编译器处理,因此 TVM 将诸如寄存器分配这样跟算子关系不大的底层优化留给了下游编译器,而只关注它们没有涉及的优化。
有博主将这种中端优化架构理解成 计算与调度分离 ,有利于在一个大的搜索空间内快速完成代码优化。
AutoTVM:搜索空间和基于学习的变换
讨论 Primitive-function scheduling 那个黄色块。
这一步感觉是一种对编译中端优化的老问题 —— 优化调度 的 tradeoff 策略。基本动机是可以完成的算子优化太多(毕竟 TVM 的目标是适配多种目标硬件平台),针对一个模型采用所有的优化固然不可能,需要根据模型的特征,选择合适数量和种类的优化;同时,我们执行编译优化的时候,还不得不着重讨论优化趟调度这个问题,同样的 Pass 序列采用不同顺序执行可能性能差别非常大,针对不同的目标平台,当然也需要选择不同的优化类型和优化趟顺序。
在具体实践中,我们很难定义一个启发式方法来做出合适的优化趟选择,以往这一步会采用手工调优(记忆犹新……),而 TVM 则采用了一种基于搜索和学习的方法来选择优化。TVM 首先定义了一组调度原语,包括循环变换、内联、向量化等优化,这些调度原语的集合定义了 TVM 可以对程序进行的可能优化的搜索空间。然后,系统会在不同的可能调度序列中搜索,以选择最佳调度组合。在 TVM 中,这个搜索过程由机器学习算法指导,也就是前面提到过多次的 AutoTVM 。实践证明,AutoTVM 提供了不逊色于手工调优的性能表现。
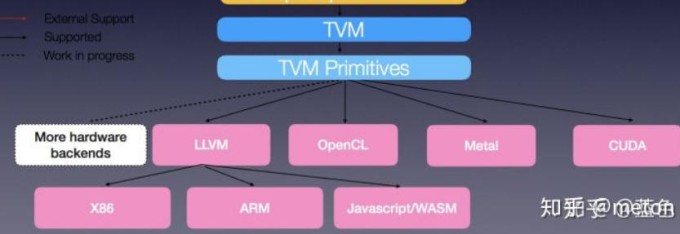
逻辑架构组成
官方文档给出如下的体系架构图:

感觉跟 LLVM 的思路还是非常像的,读了源码比较好理解一些。
🕳关于深度学习编译器
不定期填坑。
- 针对 CPU 和 GPU 平台的设计考虑代码优化
- 通过对卷积操作的变换来减少不必要的乘法和累加操作
- 通过编译时的优化 PASS 对 循环 执行进行调度(循环展开、循环分块等)
- 循环分块是一类经典的编译优化算法,被称作 Loop Tiling,或者 Loop Blocking ,基本思想是对于循环逻辑,通过将大块的循环迭代拆解成若干个较小的循环迭代块,减少由于缓存重用而引起的内存访问延迟或缓存带宽。换言之,也就是确保当这个内存元素被加载到 cache 以后,尽可能保留在 cache 中,直到被再次访问,这样就达到了减少了昂贵的片外访存的开销的目的
- 考虑多面体模型(Polyhedral Model)优化
- 编译器优化减少 load, store 指令,尽量用寄存器操作
- 类似 TVM ,更关注计算优化和高效算子代码的自动生成
- Tensorflow XLA(Accelerated Linear Algebra,加速线性代数)是一个用于优化 TensorFlow 框架计算的深度学习编译器,基于 LLVM 框架开发,前端输入是 Graph ,负责对前端定义的计算图进行优化。在优化步骤之间传递的是计算图的中间表示形式,HLO,即 High Level Optimizer(高级优化器) ,XLA 用这种中间表示形式表示正在被优化的计算图,有自己的文法和语义。
- PyTorch Glow,面向多种硬件平台的机器学习编译器和执行引擎,同样基于 LLVM 框架开发
- 参考文献
[1] T. Chen et al., “Learning to Optimize Tensor Programs.” arXiv, Jan. 08, 2019. Accessed: Jun. 12, 2023. [Online]. Available: http://arxiv.org/abs/1805.08166
[2] “Automatic Kernel Optimization for Deep Learning on All Hardware Platforms.” https://tvm.apache.org/2018/10/03/auto-opt-all (accessed Jun. 12, 2023).
[3] “Design and Architecture — tvm 0.13.dev0 documentation.” https://tvm.apache.org/docs/arch/index.html (accessed Jun. 12, 2023).
[4] V. Sze, “Efficient Processing of Deep Neural Networks: from Algorithms to Hardware Architectures,” 2019.