
不得不说荣老师讲的这课真是绝世好课,吹爆!
一开始我还跟友人说建议把这课作为编译先修课放在大二下学期开,然而在复习的过程中,我觉得让大一的同学来听都完全不过分……因此我写这辑博文也有一个小小的私心,就是留给我刚开始学 C 语言的妹妹看(当然得等她学了一阵子后再看,或许下个学期是个比较好的时机)。希望她不用重蹈我大一学得混混沌沌的覆辙,能够像我们在水群里讨论的那样,“真正地走进 C 语言”,为自己的计科之路打下一个良好坚实的基础。
内存组织基础
内存是由一系列 byte 顺序排列在一起组成的存储结构。我们常说的 8/16/32/64 位机是指用 x 位 bit 来表示 byte 的编号,说明一个 byte 由 x 位 bit 构成,可想而知内存中可以编号的 byte 个数就是 个。
byte(字节)是 C 语言最重要的基础存储单元,每一个字节都有一个编号,这个编号就是地址。一个 byte 由若干个 bit 组成,bit 是最小的存储单元,其取值为 0 或 1.
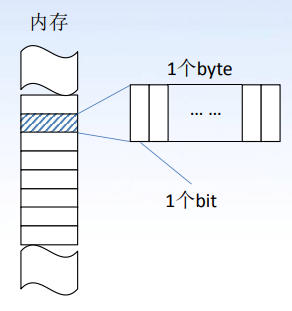
注意,地址是字节的编号,并不是字节中存储的东西的值,不管里面的每一位 bit 怎么变,这个字节的编号都是从一开始就固定好了的。
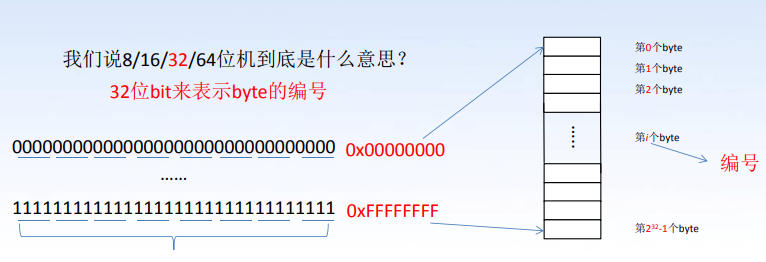
习惯上,我们“知道” ,但这不过是 C 语言规定好的,一个 byte 并不必须等于 8 bits。C 语言在头文件 <limits.h> 中定义了一个宏 CHAR_BIT,通过它规定 A byte contains CHAR_BIT bits(CHAR_BIT ≥ 8,也就是说,理论上有 1 byte > 8 bits 的可能,在 TMS320C28x Optimizing C/C++ Compiler v20.12.0.STS User’s Guide (Rev. V) 中就出现了 1byte = 16 bits 的情形)。
对象工作机制
与“面向对象”相对,印象里我们认为 C 语言是一个“面向过程”的语言,但这里我们要讨论的“对象”并不是 OOP 设计思想中封装抽象出的那个 Object。在 C 语言中,对象(Object)是一个物理性质更加强的概念,同时是 C 语言中最重要的概念。
C 标准中说,对象是 “Region of data storage in the execution environment, the contents of which can represent values”,并描述 “Objects are composed of contiguous sequences of one or more bytes”。也就是说,内存中一个或多个字节的连续序列就是对象,不准确地说这就是一块连续的内存(这个说法不官方,但我挺喜欢用的,感觉比较易于理解,因此后面基本都这样描述了),这至少说明我们在 C 编程中见到的很多东西(比如数组、指针等)都是对象。
我们可以通过对象声明(比如 int a)和内存管理函数(比如 malloc(4))来分配出一个对象。可以认为,分配对象的过程就是分配一块连续的内存的过程。

对象的属性
首地址
既然对象是一块连续的内存,那么显然定位它需要知道它的首地址。对象首地址是指对象所占用的连续字节中第一个字节的编号。
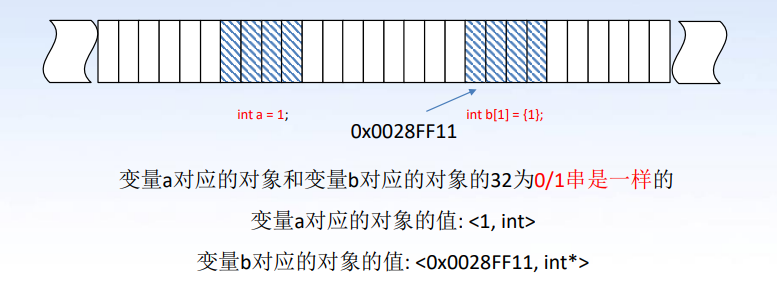
分配对象地址需要有对齐(Alignment)的要求。对齐的含义是对象的地址和由硬件条件决定的内存块大小之间需要存在一定关系——这似乎是显然的,假使现在的硬件条件规定某个对象类型只能由 4 byte 的内存块一块一块地进行存储,那么当一个变量的地址是 4 的倍数时,我们就能看到一种对齐现象,即如果我们将若干个该类型变量在内存中像垒积木一样连续地垒起来,它刚好能“卡”在一个正确的位置,如下图所示:
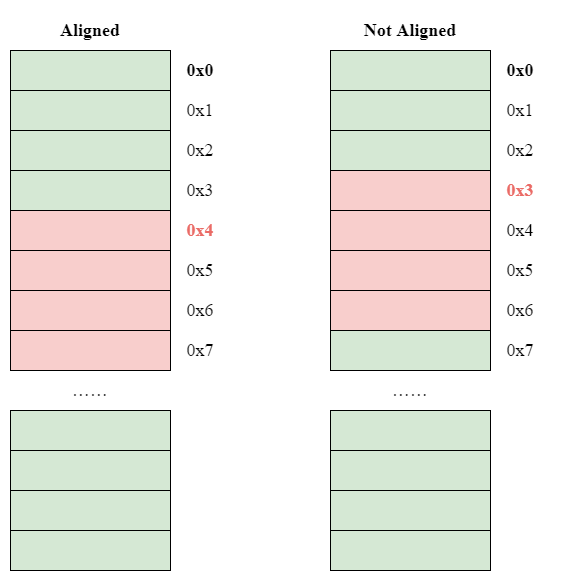
当一个对象的地址是它大小的倍数的时候,叫做自然对齐(Naturally Aligned)。显然,对齐的规则是由硬件引起的。某些体系的计算机在数据对齐这方面有着很严格的要求;在些系统上,一个不对齐的数据的载入可能会引起进程的陷入。
对象的地址是系统分配的。毕竟我们不能也没有必要在 int a 的时候显式指定它的首地址。
大小
对象的大小(size)指对象占用的连续字节个数。
类型
首先阐明,了解 C的类型系统是具有一定意义的,这可以为我们理解乃至构造其他编程语言的类型系统提供帮助。
对象类型(Object Type)主要包括:完全对象类型和不完全对象类型。下面先介绍完全对象类型。
在讨论对象类型之前,先介绍一下它的“父类”——类型(Type)。类型分为函数类型和对象类型,是用来理解一个对象或者函数返回值语义的重要依据。
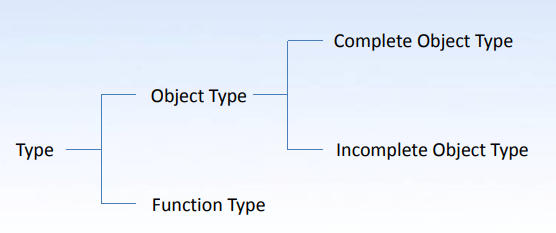
(自己搭过 IR 的人应该会对这张树状图深有体会)
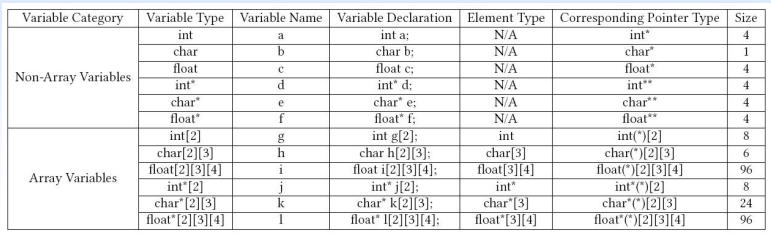
基础类型 Basic Type
C 语言类型系统中的基础类型(Basic Type)都是对象类型,它们之间的逻辑关系用图比较好描述,总结如下:
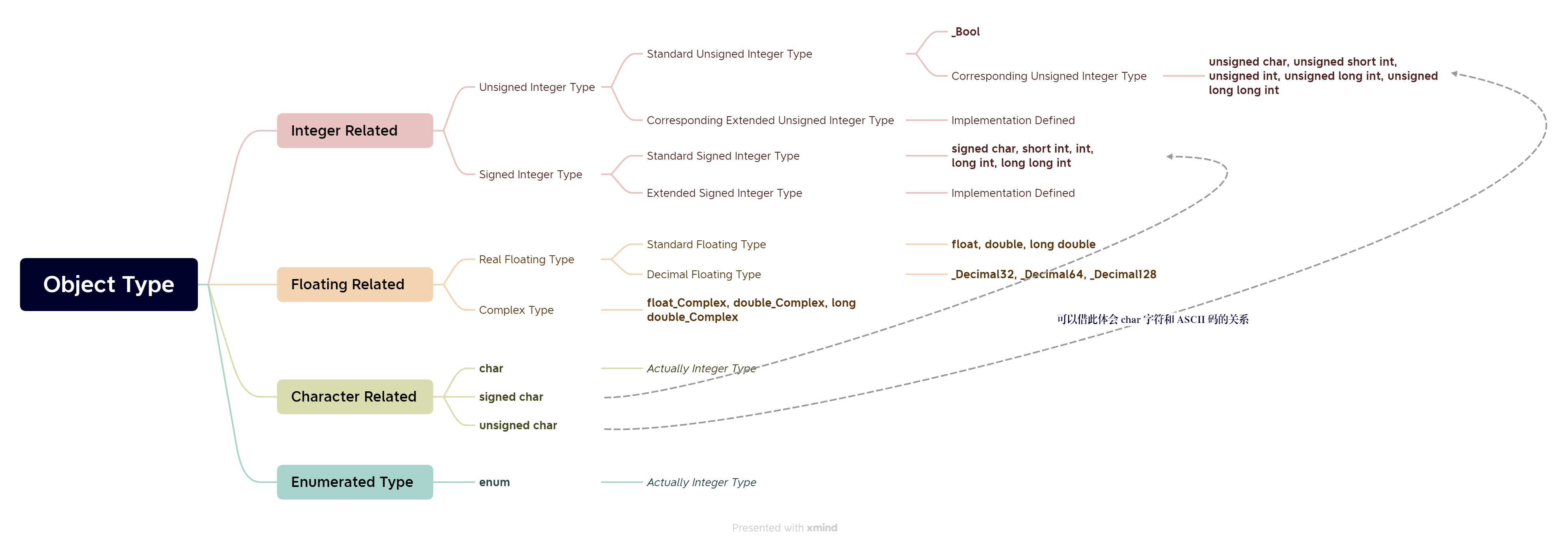
派生类型 Derived Type
可以看到,我们熟悉的一些类型,比如数组、结构体、函数、指针等都没有出现在上一节的基础类型定义中。事实上,它们属于基础类型的派生类型。
派生这个词很好地表达了它们的“非基础”特性,从实践中,我们知道派生类型基本上都由“基础”类型构造而成。C 标准将这种特性描述为 “These methods of constructing derived types can be applied recursively”,即派生类型可以递归地构造。反过来,也说明基础类型就是那些不能递归地构造的类型。
注意标红的函数类型并不是对象类型,但它是派生类型。
Array Type
数组类型(Array Type)表示的是一维数组类型,它具有两个要素:
- Element Type(T):需要是 Object Type
- Number of Elements(N)
例如,假设 T 是 int 类型,N = 2,则该类型为 int[2]。
而涉及到“多维”数组时,就需要用到前面说的“递归地构造”的特性了。荣老师上课时强调过很多次,C 语言只有一维数组,所谓的多维数组事实上是一维数组递归构造的结果。例如,假设 T 是 int[5] 类型,N = 3,则该类型为 int[3][5]。
如何验证 int[5] 是否是一个合法的对象类型?这里介绍一个特性——在 sizeof() 函数中,用括号引导的只能是对象类型,因此只要运行一下 sizeof(int[5]) 是否正确就可以验证 int[5] 是否是对象类型了。(是)
Function Type
函数类型具有的要素是:
- 返回值类型
- 参数数量和类型
即:ReturnType(argument1_Type, argument2_Type, …, argumentN_Type)
显然,函数类型也有与之对应的指针类型。

Pointer Type
规定给定任何一个 Type(T),都有对应的一个指针类型 Pointer to T,我们用一个 * 号做标记。注意一下指向数组类型的指针的 \* 号要加在那个基础类型后面的括号里。

这里也体现了一下所谓的“递归构造”的思想——我们知道任何一个 指针类型 Pointer Type 也是 Type(当然也是 Object Type),那么它当然也有对应的指针类型 Pointer to Pointer Type(即指针的指针)。
我们只要把指针类型当作一个普通的 Object Type 来看待就可以了,不要为其赋予什么特殊的地位。比如,完全可以将 int* 看成 PINT。
更细致的分类
指针类型和算术类型(Arithmetic Type,包括 Integer Type & Floating Type)共同组成了标量类型(Scalar Type)。
数组类型和结构体类型(Struct Type)共同组成了聚合类型(Aggregate Type)。
聚合类型不包括联合体类型(Union Type),因为联合体类型任一时刻只能包括一个成员类型,不符合聚合类型的定义。“一个成员类型”的含义可以近似理解成数组类型中的 N = 1,因为联合体的定义是:联合体定义的变量包含一系列的成员,特征就是这些成员共用同一块空间(所以联合体也叫做共用体),相当于所有的成员在内存视角上都合成为了一个东西。
数组类型、函数类型和指针类型共同组成了派生说明符类型(Derived Declarator Type)。
不完全对象类型
不完全对象类型是缺少必要信息确定对象大小的类型。
- 缺少元素个数的数组,如 extern int a[]
- 可变长数组(数组的 Length 未确定)
- 指用整型变量或表达式声明或定义的数组,而不是说数组的长度会随时变化,变长数组在其生存期内的长度同样是固定的。也即,变长数组一旦被声明,其大小就会保持不变直到生命期结束。
- 包含不完全对象类型的结构体 / 联合体
- void 类型
类型限定符
包括 const、volatile、restrict、_Atomic。
需要注意的是,加了限定符的类型和没加的类型(比如 const int 之于 int)是两种不同的类型!即使它们的大小、表示值都一样,但就是不同。
注意:_Atomic(TypeName) 和 TypeName 的对齐方式不一样,其他的跟自己对应的那个 TypeName 对齐方式一样。
typedef
在讲指针类型的时候,我们谈到可以将 int* 看成 PINT,以消解其扰人的“特殊性”,方便理解;在讲基础类型的时候,我们屡次在树状图中画出由 char 指向 int 的箭头,如果给它一个跟 int 相关的名字或许能够更清晰地体现出这种基础定义上的取向;在编程时,我们经常写下形如 typedef long long ll 这样的语句……在这些时刻,我们都自然地想到了为对象类型提供别名这个操作。在 C 语言中我们使用 typedef 方法实现。
注意定义数组别名的语法:
1 | typedef int AINT[2]; |
名字
对象的“名字”指的是能够在编译时将它与其他内存区别开来的那个标识符。其中的细节在后面讲左值 lvalue 时会继续深入。
- 针对通过变量声明的方式分配的对象,例如 T O,这块对象的标识符就是 O,我们将 O 认为是这块内存的名字。
- 针对通过动态分配(malloc)分配的对象,例如 malloc(4),我们认为这块对象没有标识符,即没有名字。
表示

一块对象中的各个 bit 组成的二进制串就是该对象的对象表示(Representation)。或许会有人觉得这难道不是对象的值吗?事实上,脱离了类型的值表示是缺乏意义的,Object Type + Object Representation 才能得到 Object Value. 对于同样的二进制串,不同的类型就有可能对应对象不同的值——这是显然的,比如某个大数在 unsigned int 类型下可以正常表示,但在 int 类型下其值就会是 -1。
这里介绍一个概念叫做 Trap Representation。它属于 C 语言中的一种未定义行为,描述的是无效、无意义的值,也就是上面说的“脱离了类型的值表示”。对于这样的值的读写会造成硬件的 trap exception。
——A trap representation is read by an lvalue expression that does not have character type(6.2.6.1).
——Value:precise meaning of the contents of an object when interpreted as having a specific type.
值
在 C 语言中, 值 包含了两个层面的语义:值和值的类型。我们描述值的时候都使用 <Value, Value_Type> 的对来描述,而不是单纯地描述 Value。
所有的对象都有值,且这个值和值的类型(Value Type)和对象类型有关。

对于非数组对象类型,值类型 = 对象类型,前面提到的对象表示按一定的规则转换成 Value。具体的转换细节还是放在后面讲左值的时候讲。
对于数组对象类型,< Value, Value Type > = < 第一个元素的首地址,元素类型对应的指针类型 >。比如,对于 int a[2],该对象的对象类型是 int[2],元素类型是 int,值类型是 int*。
前一节谈到的“类型不同时,尽管二进制串相等,其值也不同”就得到了解释。比如:
分配对象
前面提过了,在 C 中分配一段内存(即分配对象)的方法主要有:
- 变量声明
- 使用 malloc 分配
在这两种方法中,内存分配的过程是一样的,区别只是释放内存的不同需求。
任何对象类型分配的内存大小可以通过 sizeof 操作符获取,例如:sizeof(int)、sizeof(int[2])、sizeof(int[2][3])。
变量声明
声明一个变量需要具有 2 个基本要素:
- 对象类型 Object Type
- 约定了这段内存的类型和大小
- 变量名称(标识符,Identifier)
- 给这块内存起个别名,用于编译时识别、定位这块内存
变量声明的具体方法因声明的对象类型为非数组对象类型或者数组对象类型而有所不同。
声明变量时我们应当如何分配内存?这里需要引入内存的变量类型和内存的表示值类型的概念。
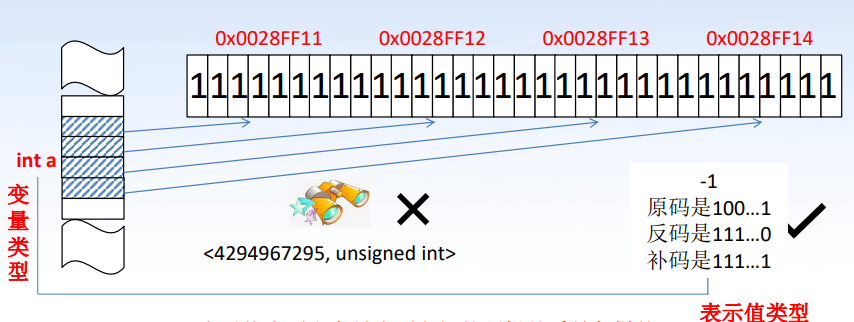
- 内存的变量类型是 Physical View,指导在内存分配时按什么类型去申请内存
- 内存的表示值类型是 Logical View,是这块内存从外部观察时能看到的值的类型,我们在观察时,需要透过变量类型的视野——这决定了你将 4294967295 看成一个大整数还是 -1.
假设内存表示值记为 <V, V_T>,内存对应的变量类型记为 Obj_T:
若 Obj_T 是非数组类型,则 V_T = Obj_T,V 是通过 Obj_T 去观察这段内存获得的值。
若 Obj_T 是数组类型,则 V_T 是该数组类型中元素变量类型对应的指针类型,V 是数组第一个元素所处内存的第一个字节编号(即首字节地址)。
非数组对象类型
显然的。

指针需要注意一下:


数组对象类型
需要注意识别数组变量声明中的对象类型和变量名称。

以 float[2][3] 为例,它的对象类型是 float[2][3],但作为数组类型,它的元素对象的对象类型(Element Type)是 float[3].
这里也需要注意一下指针。由数组类型的定义可知,显然指针对象类型作为一个对象类型,也可以用来构造数组类型,即将指针类型作为数组对象中元素的对象类型,构建一个“指针数组”。
指针数组跟数组指针的外表区别在于那个**括号。**括号可以看作是我们特别把指针的标识框了出来,告诉你这是一个指针,用一个错误的表述来描述就像:
int(*)[2] ==> (int[2])*
而在“指针数组”这里没有加括号,是旨在将那个标识指针身份的 * 号与前面的基础类型标识结合,更像一个新的类型名称(回想一下前面讲指针类型的时候,我们已经强调过将指针类型看成一个完整的新类型这个思想了!),这样可以更自然地将该整体看作一个数组而非一个指针。

这里放两张图区别一下(其实理解了对象类型这个系统以后就很容易搞懂了):


如果声明的时候不指定数组长度(如 int e[] = {1, 2} ),则数组长度等于初始化列表中元素的个数。
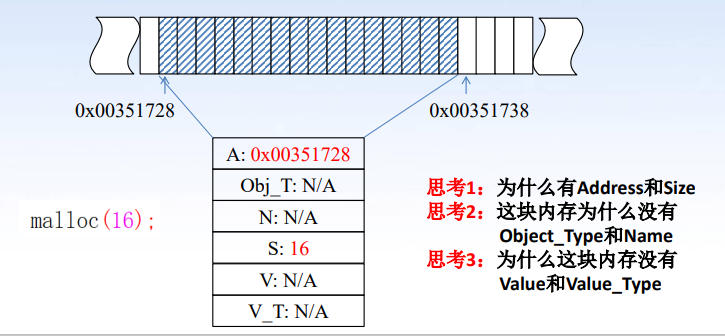
内存六元组模型
该六元组模型是一个为了让大家更好地了解分配的内存而提出的一个逻辑模型(演的),事实上是用以描述对象,也即一块连续内存的。直接看图:

这六个元素的取值规则表述如下:
- Address:由系统分配,一旦确定无法更改
- Object_Type 和 Name 是变量声明对应的变量类型和变量名
- Size 是这块内存的大小(字节数)
- Value 和 Value_Type 的取值根据 Object_Type 来确定,规则前面讲过了
对于通过变量声明语句声明的对象,为其构造六元组的过程是很显然的。那么对于通过 malloc 语句分配的对象呢?答案如下图所示:
函数类型六元组
借用对象类型六元组的概念,也可以设计一个六元组描述函数。此时:
- Address:函数入口地址
- Func_T:函数类型
- N:函数标识符
- 函数类型没有大小,sizeof 无效,因此 S 单元格的值始终为 N/A
- 表示值 V 等于 Address
- V_T 是 Func_T 对应的指针
内存赋值
为内存赋值有两种途径:一是变量初始化,即声明变量的同时为这块内存赋值,例如 int a = 2;二是变量赋值,即先声明变量,再为这块内存赋值,比如 int a; a = 2。
从六元组的定义和值的定义来看,数组对应的内存整体赋值只能通过变量初始化,并且数组对应的内存表示值不会发生任何变化!(毕竟 Value 始终取的是首元素地址编号)这似乎有点反直觉,我们不是经常写下形如a[1] = 3这样的句子吗?但请回到值的定义上看,这个赋值语句的操作改变的是那块内存对应的二进制串,然而数组类型的值与那个二进制串的取值没有任何关系。
后面对左值和数组的讲解也会帮助解决这个问题,这里暂且搁下。
对于变量初始化过程,填充六元组的过程是显然的。
对于变量赋值,我们先讨论前半句 int a。此时没有为内存赋值,那么对象 a 对应的那段内存有 Value 吗?答案是有,因为在前面讲值的时候我们已经说过,对于数组类型,Value 是第一个元素的首地址,此时已知;对于非数组类型对象,其 Value 是将这段内存的表示按一定规则转换得到的,表示已知(直接查看这段内存对应的二进制串即可),因此也有 Value,只不过它不太可能是我们想要的 Value,有可能是之前用过这段内存的对象剩下的(此时我们看不懂这段内存的信息,通常用标识符 Undefined 来记录它),在某些语言里也有可能会被初始化——从这个角度出发,变量合理的初始化是良好的防错性编程习惯。
然后讨论后半句 a = 2。在 C 语言中,只能对一块内存进行赋值,因此,对于等号左边的表达式,我们要求必须能通过它识别出一块有效内存。因此赋值的过程就是对等号右边的表达式取值,然后赋给等号左边表达式对应的待赋值内存。
我们屡次提到的“左值”——lvalue(其实大名不是 left value, 是 locator value),指的就是一个能定位内存的表达式,相对应的右值是一个表达式的返回值。
左值中识别出来的内存,一旦跟任何操作符结合,就变成了取值操作(因为需要取其返回值跟操作符另一侧的表达式进行运算),导致其无法定位一块合法的内存,失去左值的身份。

如何通过表达式定位到内存呢?有两种方式:
- 通过变量名定位内存
通过六元组模型可以知道每一块声明过的内存都会对应一个 Name 以供识别,编译的时候会在符号表里查找这个名字,取这个名字记录下的内存地址就可以了。
- 通过 * 运算符定位内存
假设一个表达式 exp 的取值是 <Value, Value_Type>,如果 Value_Type 是一个指针类型,则可以用 *exp 的方式定位到 Value 对应的字节编号开头的一段内存,这就是所谓的指针的原理了。比如,对于取值是 <1, int*> 的表达式 exp,*exp 定位到的是开头地址为 0x1 的那段内存。
内存读取
读取内存相关信息的操作步骤如下:
-
通过表达式定位内存:具体方法见上节
-
识别对内存的操作类型:对每一块内存都有 3 种操作类型,每一种都获得一个返回值,它们的操作格式如下(按优先级):
- 获得内存的首地址:&(表达式)
- 获得内存的大小:sizeof(表达式)
- 获得内存的表示值:表达式
-
获得相应的返回值:返回值是一种 Value,也就是说,包括返回值的类型和返回值的值。针对表达式 exp 对应的内存六元组,3 种操作类型对应的返回值是(按优先级):
- &exp → <Address, Obj_T*>
-
sizeof(exp) → <Size, size_t>
- size_t 是用来表示内存大小的数据类型- exp → <Value, Value_Type>